본 논문은 IJCAI 2019에서 발표된 논문입니다.
고려대학교의 임희석 교수님 및 자연어처리 연구실에서 발표한 논문입니다.
NLP의 Sentiment Analysis에 대해 새로운 모델을 제안한 논문입니다.
https://sites.google.com/view/emotionx2019
EmotionX 2019
EmotionX 2019 Welcome to EmotionX 2019, the shared task of SocialNLP 2019. Participants are challenged to predict the emotions induced by dialogue utterances by classifying each utterance into one of four label candidates: joy, sadness, anger, and neutral.
sites.google.com
About EmotionX 2019


논문에서 EmotionX에 대해서 언급이 되어 해당 내용을 찾아봤습니다.
일종의 NLP Challenge로써, 데이터셋을 학습해 joy, sadness, anger, neutral를 예측하는 challenge입니다.
꼼꼼히 논문을 읽으며, 공부해보도록 하겠습니다.
논문 링크 : https://arxiv.org/abs/1906.11565
Abstract

논문의 요약 부분입니다. 핵심 내용은 다음과 같습니다.
- transferable language model, dynamic max pooling을 기반으로 contextual emotion classifier을 제안한다.
- 감성 분석의 대표적인 EmotionX에서 contextual information을 고려할 필요가 있었고, 클래스 불균형 문제를 다루어야 했다. 이를 해결하기 위해 self-attention, weighted cross entropy loss를 활용했다.
- post-training, fine-tuning mechanisms을 활용해 성능을 끌어올렸다.
- 실험은 감정 상태가 레이블된 Friends와 EmotionPush 데이터셋을 사용했다.
- 결과적으로, EmotionX 2019에서 state-of-the-art를 달성했다.
Introduction


논문의 서론 부분입니다.
감성 분석(Sentiment analysis)에 대한 내용의 소개와 함께 글을 시작합니다.
전통적인 감성 분석은 주변의 문맥을 고려하지 않고 오직 target sentence 혹은 document 하나만을 고려해 분석하며, 논문에 따르면 이러한 문제를 해결하기 위해서 문맥 정보를 포함한 데이터셋이 등장했으며, 더 나아가 mult-party conversation 데이터셋이 등장합니다.
데이터셋의 한 예시인 Table 1을 제시하며 세부적인 설명이 기재되어 있습니다.
그리고 마지막엔 Self-attention의 등장으로 인해 성능이 비약적으로 발전되었음을 언급합니다.
// Self-attention은 Transformer의 개념이 등장한 논문인 "Attention is all you need"에서 제안한 내용입니다.

서론의 마지막 부분입니다.
EmotionX의 task를 바탕으로 contextual emotion classifier을 제안한다고 주장합니다.
제안하는 모델은 transferable language model, dynamic max pooling을 활용하며 이를 통해 문맥 정보를 활용할 수 있다고 주장합니다.
Related Work
2.1 Pre-trained language models

해당 섹션에서는 Pre-trained language model에 대한 내용이 설명되어있습니다.
지금까지 ELMo, GPT, BERT와 같은 pre-trained 모델을 사용해 많은 NLP task에 적용되었고, 좋은 성과를 달성했다 언급합니다. 대량의 말뭉치를 기반으로 학습해 deep contextualized embedding을 만들 수 있고 좋은 성능을 보입니다.
논문에서는 이전의 몇몇 실험에서도 이와 같은 pre-trained model을 사용해 감성 분석을 진행한 실험이 있었으며 좋은 성능을 보였지만, 하나의 문장만을 대상으로 하였거나 문맥 정보를 기반으로 예측을 수행하지는 않았다고 주장합니다.
이에 논문에서 진행한 접근법은 이러한 점을 해결했다고 언급합니다.
2.2 Sequence labeling

관련 연구 중 Sequence labeling에 관한 내용입니다.
진행하는 실험이 dialogue act sequnce labeling task와 비슷하다고 생각했으며,
그에 대한 이전의 관련 연구들을 소개합니다.
논문에서는 대화 수준에서의 pre-trained model을 기반으로 emotion detection을 위한 sequnce labeing에 대한 연구는 처음이라고 주장합니다.
Model Description
논문에서 제안하는 모델에 대한 설명 부분입니다.
3.1 Overview


Figure 1을 통해 transferable language model과 dynamic max pooling을 조합한 contextual emotion classifier을 설명하며 제안합니다.
간단한 모델의 동작은 다음과 같습니다.
(1) 입력 발화는 BPE 알고리즘에 의해 토크나이징됩니다.
(2) 언어 모델은 토큰화된 입력에 대해 deep contextualized token representation에 임베딩하며, dynamic max pooling으로 발화 표현(utterance representations)으로 변환됩니다.
(3) 분류기를 통해 상황에 따른 감정을 감지합니다.
3.2 Input Embedding

Input Embedding에 관한 내용입니다.
- 입력 값은 BPE tokenizxer에 의해 lower-cased(소문자 처리) 및 토크나이징 처리가 진행됩니다.
- 같은 대화 내에서는 모든 토큰들 사이에 [SEP]라는 토큰들이 추가됩니다.
3.3 Language Model Encoder

모델의 인코더 부분에 대한 설명입니다.
논문에서는 트랜스포머 기반의 BERT 모델을 채택했는데, 이는 long term dependecy problem에 도움이 되고 문맥 정보를 효율적으로 탐지(capture) 할 수 있으며 pre-trained parametrs가 다른 task를 수행함에 있어서도 뛰어난 성능을 보이기 때문입니다.
성능을 더 끌어올리기 위해서 masked language model(MLM), next sentence prediction(NSP), fine-tuned의 과정을 수행했다고 합니다.
3.4 Imblanced Emotion Classification

Figure 1의 Classifier은 두 개의 linear layer, 활성화 함수인 SELU, Dropout의 과정들을 거친다고 설명합니다.
SELU는 정규화 과정이 포함되어 있어 경사 하강법이 빠르게 수렴함을 돕고 Dropout을 통해 overfitting을 방지하고자 함을 언급합니다.
또한, Table 2를 제시하며 Friends, EmotionPush 데이터셋의 클래스 불균형 문제에 대해 언급한다.
표를 보면 두 데이터셋 모두 Neutral, Joy 클래스가 절반이 넘는 불균형을 보임을 알 수 있습니다.
이를 해결하기 위해 weighted corss entropy(WCE)를 사용했으며 그에 대한 공식을 기재했습니다.
Empirical Study
제안하는 모델에 대해 실험을 수행하고 그 결과에 대해 discuss하는 섹션입니다.
4.1 Dataset

EmotionX 2019와 Friends, EmotionPush 데이터셋에 대한 기본적인 설명 부분입니다.
Frineds 데이터셋은 유명 TV 프로그램의 multi-party conversations이며,
EmotionPush 데이터셋은 페이스북과 같은 소셜 네트워크 메신저의 대화 데이터셋입니다.
4.2 Experimental Setup

실험 환경에 대한 내용입니다.
기본적인 batch size, epoch, learning rate 그리고 post-train에 대한 설명이 기재되어 있습니다.
4.3 Evaluation Metric

모델 학습 시에 사용한 평가 지표에 대한 내용입니다.
논문에서는 micro f1 score를 사용해 훈련을 진행했습니다.
4.4 Results and Analysis
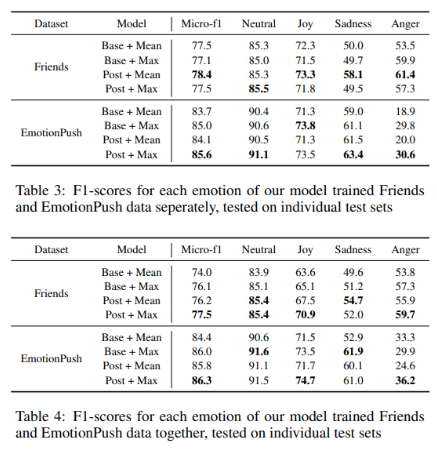

실험 결과와 분석에 대한 내용입니다.
논문에서 제안한 transferable language model + post-trained이 뛰어난 성능을 보임을 table 3,4를 통해 입증하고 있으며 자세한 내용에 대해 더 서술되어 있습니다.
또한 제출 버전에 대해서는 k-fold cross validation (k=5) 을 적용해 most voted된 결과에 대해 레이블을 진행했다고 설명합니다.
Conclusion

논문의 결론 부분입니다.
논문에서는 transferable language model과 dynamic max pooling으로 구성된 Contextual emotion classifier을 제안했으며 caputre contextual information, understand informal text dialogues, class imbalance의 3가지 문제에 대한 해결을 이루었다고 주장합니다.
또한, 그 성능은 SOTA(state-of-the-art)를 달성했습니다.
그러나 입력 토큰에 대해 maximum length를 설정했으므로 이에 대한 문제를 향후 연구를 통해 극복하겠다고 설명합니다.
공부하며 느낀 점
NLP에 다양한 task들이 존재하는데 그 중 감성 분석(Sentiment Analysis)에 대한 내용이었습니다.
감성 분석에 대한 중요성이 종종 언급되곤 하지만 감성 분석에 대한 내용에 대해 무지한 상태였습니다.
이 논문을 통해 감성 분석에 대해 조금이나마 이해를 할 수 있었고, NLP에서 감성 분석 분야에 대한 흥미를 느낄 수 있었습니다.
기회가 온다면 이러한 실험을 진행해보고 더 재미있게 공부를 할 수 있지 않을까라는 생각이 들었습니다.
역시 자연어 처리는 공부하면 할수록 흥미 있고 재미있지 않나라는 생각을 할 수 있었습니다.ㅋㅋ
댓글