지난번 포스팅에 이어서 나머지 열(column)인 Group_A 와 Group_B를 정리해보도록 하겠습니다.
주피터 노트북으로 구현
In [11] :
group_A = train_df['Feature_Group_A']
group_A[0]
- Group A와 Group B의 경우 한 행에 배열의 형태로 데이터가 들어가 있었습니다. 256개의 원소를 가지는 배열이었으며 모든 행이 같은 형태였습니다.
- 의미도 모르는 이 데이터들을 어떻게 처리해야 할지 고민을 했습니다. 그래서 그냥 단순하게 데이터마다 하나씩 column을 지정해서 값을 정리하기로 했습니다. (Group_A의 256개의 값들을 a_0, a_1, a_2 ... 이런 방식으로)
In [12] :
characters = "[] "
for x in range(len(group_A)):
for y in range(len(characters)):
group_A[x] = group_A[x].replace(characters[y],"")
print(group_A)group_A[0]
- 이전 포스팅과 동일한 방식으로 [ , ] , 공백까지 전부 제거했습니다.
In [13] :
feature_group_a_df = pd.DataFrame()In [14] :
empty_list = []
for x in range(256):
empty_list.append("a_%d" % (x))
print(empty_list)In [15] :
for x in range(256):
feature_group_a_df.insert(0, empty_list[x], [0])In [16] :
feature_group_a_df = feature_group_a_df[empty_list]
feature_group_a_df
- 그리고 feature_group_a_df 라는 변수 명의 새로운 데이터프레임을 만들고, a_0 부터 a_255 까지의 column명이 들어간 배열을 만들어 데이터프레임에 추가했습니다.
In [17] :
for x in range(len(group_A)):
temp = group_A[x].split(',')
feature_group_a_df = feature_group_a_df.append(pd.Series(temp, index=feature_group_a_df.columns), ignore_index=True)feature_group_a_df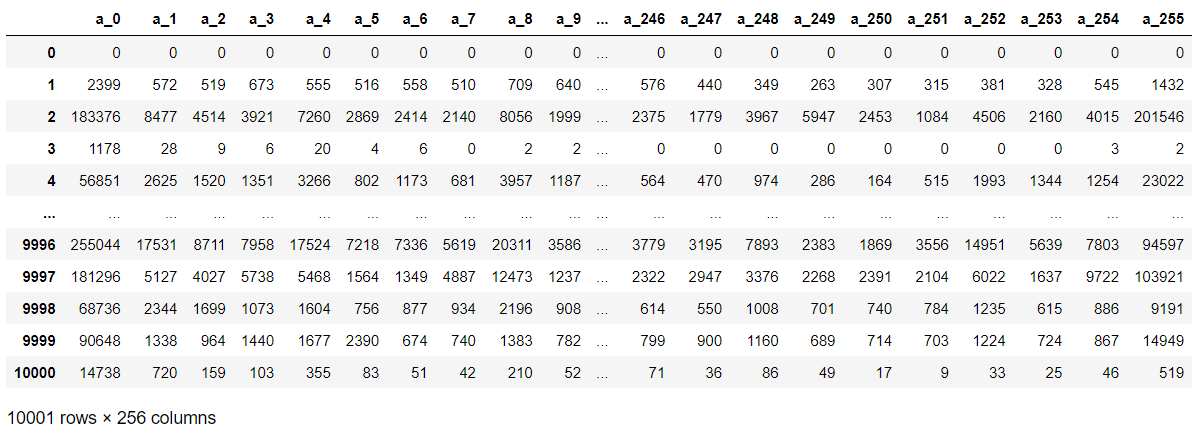
- .append() 함수로 판다스의 Series형태로 데이터를 전부 넣어줬습니다. 위와 같은 결과가 나왔는데, 첫 번째 행이 그대로 남아 있는 모습입니다.
In [18] :
feature_group_a_df = feature_group_a_df.drop([0])
feature_group_a_df = feature_group_a_df.reset_index(drop=True)
feature_group_a_df
- .drop() 함수로 첫 행을 제거하고, .reset_index()함수로 index를 재정렬했습니다. 그 결과, 사진과 같이 제대로 정리된 것을 확인할 수 있습니다.
In [19] :
train_df = pd.concat([train_df, feature_group_a_df], axis=1)
train_df = pd.concat([train_df, feature_group_b_df], axis=1)
train_df = train_df.drop(columns=['Feature_Group_A'], axis=1)
train_df = train_df.drop(columns=['Feature_Group_B'], axis=1)
- Feature_Group_B 또한 같은 과정을 거쳐 정리했습니다. (과정이 똑같기에 코드 생략)
- 사진과 같이 522개의 속성을 가진 데이터프레임으로 정리된 것을 확인할 수 있습니다.
- Feature_Group_C 에서 나온 printabledist 열에서 나온 데이터도 Group A, B와 같은 형태인 것을 확인할 수 있습니다. 이를 똑같이 정리해서 정리해주면,

사진과 같이 618개의 속성을 가진 데이터프레임이 완성되었습니다.
제가 가공한 이 데이터를 기반으로 교내 대회를 진행했으며, XGBoost와 LightGBM을 통해 모델 학습을 시켰습니다.
특성 수가 너무 많은 것 같아 PCA, 특성 선택 등 여러 가지 방법도 시도해 보았고,
Accuracy를 최대한 높이기 위해 앙상블 기법을 공부해 적용해보기도 하고,
많은 것들을 배울 수 있는 대회였던 것 같습니다.
도움이 되셨다면 아래 광고 한 번만 클릭해주세요 감사합니다!
'머신러닝 & 딥러닝 > 데이터 분석' 카테고리의 다른 글
| 데이터프레임 - 그룹화된 데이터 열(column) 가공하기(1) : .json_loads() && .from_dict() (0) | 2021.11.02 |
|---|---|
| EDA - 결측치/결측값(missing values) 분석과 barplot을 이용한 데이터 시각화 (0) | 2021.08.31 |


댓글