토크나이징(tokenizing)
일반적으로, 자연어 처리를 하기 위해서는 문장을 일정 의미를 지닌 작은 단어들로 나누어야 합니다.
가장 기본이 되는 단어를 토큰(token)이라 합니다.
말뭉치(혹은 문장)가 주어졌을 때, 이러한 토큰 단위로 나누는 작업을 토크나이징(tokenizing)이라고 합니다.
주로 텍스트 전처리 과정에서 사용되고, 이 과정에 따라 성능 차이가 날 수 있습니다.
한국어 토크나이징?
띄어쓰기와 단어의 변화가 적은 영어와 달리, 한국어는 문법적으로 복잡하고 한국어 토크나이징을 구현하기 위해서는 한국어 문법에 대해 깊이 있는 이해력이 필요합니다. 하지만, 이 기능을 지원하는 라이브러리가 존재하며 이를 사용해 한국어를 토크나이징 해보도록 하겠습니다.
형태소를 토큰 단위로 쓰며, 형태소는 일정한 의미가 있는 가장 작은 말의 단위입니다.
KoNLPy와 KKma, Komoran, Okt
위에서 언급한 한국어 자연어 처리를 위한 파이썬 라이브러리가 있습니다.
바로 'KoNLPy (코엔엘파이)' 입니다.
KoNLPy이 에서는 여러 가지의 형태소 분석기를 제공합니다.
그 중 3가지를 소개하겠습니다.
1. KKma
Kkma는 서울대학교 IDS 연구실에서 자연어 처리를 위해 개발한 한국어 형태소 분석기입니다.
'꼬꼬마'로 발음합니다.
KKma(꼬꼬마) 홈페이지 : http://kkma.snu.ac.kr/
위의 홈페이지에서 자세한 정보를 확인할 수 있습니다.
2. Komoran
Komoran은 Shineware에서 개발한 자바(Java) 기반의 한국어 형태소 분석기입니다.
'코모란'으로 발음합니다.
코모란은 공백이 포함된 형태소 단위로 분석이 가능합니다.
Komoran(코모란) 홈페이지 : https://www.shineware.co.kr/products/komoran/
3. Okt (Open-source Korean Text Processor)
Okt는 트위터에서 개발한 Twitter 한국어 처리기에서 파생된 오픈소스 한국어 처리기입니다.
Okt GitHub : https://github.com/open-korean-text/open-korean-text
주피터 노트북으로 실습하기
Komoran
In [1] :
from konlpy.tag import Komoran
komoran = Komoran()- konlpy.tag 패키지에서 Komoran 라이브러리를 불러옵니다.
- Komoran() 함수를 선언해 사용할 준비를 해줍니다.
In [2] :
text = "자연어 처리 공부는 흥미롭다."- 분석할 텍스트를 설정합니다.
In [3] :
morphs = komoran.morphs(text)
print(morphs)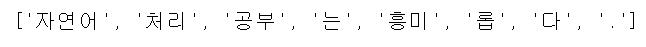
- .morphs() 함수는 입력 값을 형태소 단위로 토크나이징합니다. 토크나이징된 형태소들은 리스트 형태로 반환됩니다.
- 결과값을 통해 형태소 단위로 나누어진 값을 확인할 수 있습니다.
In [4] :
pos = komoran.pos(text)
print(pos)
- POS tagger라 부릅니다.
- .pos() 함수를 사용해 인자로 입력한 값에서 형태소를 추출한 뒤 품사 태깅을 진행합니다. 추출된 형태소와 그 형태소의 품사가 튜플 형태로 묶여 리스트로 반환됩니다.
In [5] :
nouns = komoran.nouns(text)
print(nouns)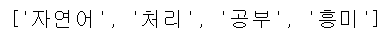
- .nouns() 함수를 사용해 품사가 명사인 토큰들만 추출할 수 있습니다.
Kkma
In [1] :
from konlpy.tag import Kkma
kkma = Kkma()
text = "자연어 처리 공부는 흥미롭다."- Kkma도 역시 konlpy.tag 패키지에서 불러올 수 있습니다.
- 진행했던 코드와 동일한 형태로 진행했습니다.
In [2] :
morphs = kkma.morphs(text)
print(morphs)
pos = kkma.pos(text)
print(pos)
nouns = kkma.nouns(text)
print(nouns)
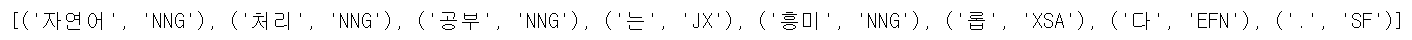
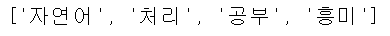
- Komoran과 동일하게 .morphs(), .pos(), .nouns() 함수의 사용이 가능합니다.
In [3] :
sentences = "올해는 진짜 춥겠지? 롱패딩 사야지."
s = kkma.sentences(sentences)
print(s)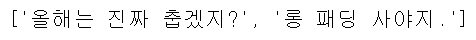
- Kkma(꼬꼬마)는 .sentences() 함수 기능을 제공하는데, 인자로 입력한 여러 문장을 분리해주는 역할을 합니다. 분리한 값을 리스트로 반환합니다.
Okt
In [1] :
from konlpy.tag import Okt
okt = Okt()
text = "자연어 처리 공부는 흥미롭다."
morphs = okt.morphs(text)
print(morphs)
pos = okt.pos(text)
print(pos)
nouns = okt.nouns(text)
print(nouns)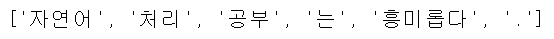
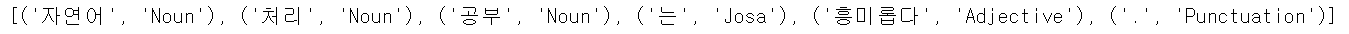

- Okt 또한 위의 예제들과 사용법이 동일합니다.
- Okt가 보통 속도가 더 빠르지만, 정확한 품사의 태깅이 필요한 경우 Kkma와 Komoran을 쓴다고 합니다.
In [2] :
text = "자연어 처리 재밌엌ㅋㅋ"
print(okt.normalize(text))
print(okt.phrases(text))
- Okt는 .normalize()함수로 정규화기능을 제공합니다. 오타가 섞인 문장을 정규화해 처리하는데 좋습니다.
- .phrases() 함수로 입력 값을 어구 단위로 추출하는 기능도 제공합니다.
글의 내용이 도움되셨다면, 아래의 광고 클릭 한 번만 부탁드립니다. 감사합니다!
'머신러닝 & 딥러닝 > 자연어처리' 카테고리의 다른 글
| [자연어 처리/NLP기초] 2. 단어 이해시키기(1) - 시소러스와 WordNet (0) | 2022.02.19 |
|---|---|
| [자연어 처리/NLP기초] 1. 자연어 처리란? (0) | 2022.02.14 |
| 자연어처리(NLP)에 쓰이는 13가지 기초 용어 알아보기 (0) | 2021.11.29 |
| 파이토치 기초 텐서(Tensor) 인덱싱, 슬라이싱, 합치기(연결) - torch.index_select(), cat(), stack() (0) | 2021.11.28 |
| 파이토치 기초 텐서(Tensor) 연산 및 유용한 함수 - torch.add(), arange(), view(), sum(), transpose() (0) | 2021.11.27 |


댓글