머신러닝 시스템의 종류
2. 머신러닝 시스템의 종류
머신러닝이란 https://seokii.tistory.com/48?category=1054781 1. 머신러닝(Machine Learning, 기계학습)이란 무엇인가? 머신러닝(기계학습)과 딥러닝에 대해 공부하다가, 남들에게 설명할 수 있을 만큼 기초 이..
seokii.tistory.com
지난 글에서 머신러닝 시스템의 종류에 대해 정리했습니다.
주의해야 할 6가지
적은 양의 훈련 데이터
기본적으로 대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 합니다.
아주 간단한 문제에서조차도 수천 개의 데이터가 필요하고 이미지나 음성 인식 같은 복잡한 문제라면 수백만 개가 필요할지도 모릅니다.
따라서, 항상 최대한 많은 양의 데이터를 확보하기 위해서 노력해야 합니다.
대표성 없는 훈련 데이터
훈련한 모델이 일반화가 잘 되려면 우리가 일반화하기 원하는 새로운 사례를 훈련 데이터가 잘 대표하는 것이 중요합니다.
그렇지 않다면 샘플링 잡음(sampling noise)[우연에 의한 대표성 없는 데이터]이 생기며, 표본 추출 방법이 잘못된 경우 샘플링 편향(sampling bias)이 발생하게 됩니다.
낮은 품질의 데이터
훈련 데이터에 에러, 이상치(outlier), 잡음이 많다면 머신러닝 시스템이 데이터로부터 패턴을 찾기 어려워 좋은 성능을 기대할 수 없습니다. 따라서, 데이터 정제에 많은 시간을 투자할만한 가치는 충분하며 많은 데이터 사이언티스트들이 이 과정에 많은 시간을 쓰고 있습니다.
관련 없는 특성
훈련 데이터에 관련 없는 특성이 적고 관련 있는 특성이 충분해야 시스템이 충분히 학습할 수 있습니다.
성공적인 머신러닝 프로젝트의 핵심은 훈련에 사용할 좋은 특성들을 찾는 것입니다.
이 과정을 특성공학(feature engineering)이라 하며 이 과정에서 특성 선택(feature selection), 특성 추출(feature extraction) 등을 진행하게 됩니다.
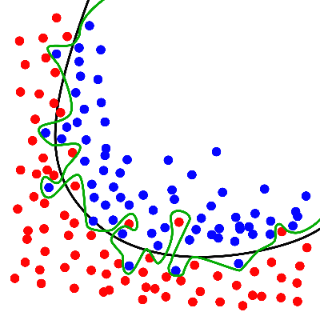
과대적합
과대적합은(overfitting) 말 그대로 학습 데이터를 과하게 학습하는 것을 뜻합니다.
훈련 데이터에만 너무 잘 들어맞아 일반화 성능이 낮아지는 현상입니다.
아래의 사진에서 녹색선이 모델이 과대적합된 경우라고 볼 수 있습니다.
과대적합을 방지하기 위해 모델이 제약을 가하는 것을 규제(regularization)이라 합니다.
과소적합
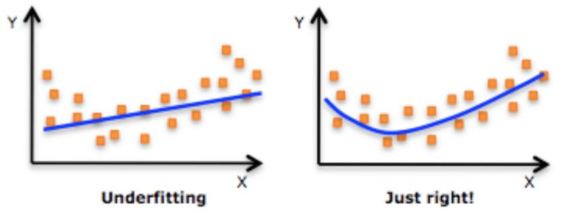
과소적합(underfitting)은 과대적합의 반대입니다.
모델이 너무 단순해 데이터의 내재된 구조를 학습하지 못할 때 발생하게 됩니다.
아래의 사진이 과소적합의 예시입니다.
과소적합은 파라미터가 많은 모델을 선택, 특성 공학을 통해 더 좋은 특성을 제공, 모델의 제약을 줄이기 등의 방법으로 해결할 수 있습니다.
'머신러닝 & 딥러닝 > 기초 이론' 카테고리의 다른 글
| [머신러닝/딥러닝 기초] 6. 퍼셉트론의 한계와 다층 퍼셉트론(multi-layer perceptr) (0) | 2022.02.09 |
|---|---|
| [머신러닝/딥러닝 기초] 5. 퍼셉트론(Perceptron) 이론과 간단 구현 - 2 (0) | 2022.02.09 |
| [머신러닝/딥러닝 기초] 4. 퍼셉트론(Perceptron) 이론과 간단 구현 - 1 (0) | 2022.02.09 |
| [머신러닝/딥러닝 기초] 2. 머신러닝 시스템의 종류 (0) | 2022.02.08 |
| [머신러닝/딥러닝 기초] 1. 머신러닝(Machine Learning, 기계학습)이란 무엇인가? (0) | 2022.02.08 |




댓글