NLP Tutorial
https://github.com/Seokii/Korean_NLP_Tutorial
GitHub - Seokii/Korean_NLP_Tutorial: 한국어 자연어처리 튜토리얼
한국어 자연어처리 튜토리얼. Contribute to Seokii/Korean_NLP_Tutorial development by creating an account on GitHub.
github.com
자연어처리를 공부하며 여러 한국어 NLP Task에 대한 예시 코드를 작성하고자 만들었습니다.
예시 코드를 통해 저와 같은 자연어처리 입문자들에게 도움이 되었으면 합니다 :)
해당 깃허브 주소를 통해 작성한 주피터 노트북 파일을 다운받거나 확인할 수 있습니다.
Dataset
Naver sentiment movie corpus (nsmc)
GitHub - e9t/nsmc: Naver sentiment movie corpus
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com
링크에서 제공하는 네이버 감성 분류 데이터를 통해 감성 분석을 진행하였습니다.
Jupyter Notebook
라이브러리 불러오기
In [1] :
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
from sklearn.model_selection import train_test_split
from konlpy.tag import Komoran필요한 라이브러리를 불러옵니다.
- 모델링에 필요한 pandas, numpy, tensorflow와 시각화를 위한 matplotlib, seaborn를 불러옵니다.
- 한국어 형태소 분석을 위해 KoNLPy를 사용했습니다.
- 단어 사전을 만들기 위해 파이썬 패키지의 Counter 라이브러리를 사용했습니다.
- 사이킷런을 활용해 데이터 분할을 진행했습니다.
데이터 불러오기
In [2] :
train = pd.read_table("../../dataset/nsmc_train.txt")
test = pd.read_table("../../dataset/nsmc_test.txt")In [3, 4] :
train.head()test.head()
In [5, 6] :
print(f"train shape => {train.shape} \ntest shape => {test.shape}")train.columns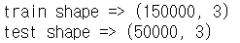
시각화
Seaborn의 countplot과 matplotlib의 pie chart를 사용해 훈련 데이터의 라벨값의 수와 비율을 확인합니다.
In [7] :
sns.set_theme(style="darkgrid")
ax = sns.countplot(x="label", data=train)
In [8] :
labels, frequencies = np.unique(train.label.values, return_counts=True)
plt.figure(figsize=(5,5))
plt.pie(frequencies, labels = labels, autopct= '%1.1f%%')
plt.show()

- 라벨 값이 균등하게 분포되있는것을 확인할 수 있습니다.
결측 값 확인
In [9, 10] :
train.isnull().sum()test.isnull().sum()
- train, test 데이터 모두 결측 값이 존재함을 확인할 수 있습니다.
- 데이터 전처리 과정에서 이를 다루도록 하겠습니다.
데이터 전처리
다음과 같은 데이터 전처리를 수행하는 부분입니다.
- 데이터 중복제거 (drop_duplicates)
- 결측 값 제거 (dropna)
- 한국어 토크나이저를 활용한 토큰화 (Komoran)
- 불용어 제거 (조사, 구두점, 접미사 종류)
- Bag of Words, word to index, index to word 구현
- 문장 길이 분포와 적절한 최대 문자 길이 지정
- 최대 문자 길이에 따른 패딩 추가 (pad_sequences)
In [11, 12, 13] :
tokenizer = Komoran()
def preprocess(train, test):
train.drop_duplicates(subset=['document'], inplace=True)
test.drop_duplicates(subset=['document'], inplace=True)
train = train.dropna()
test = test.dropna()
print(f"train shape => {train.shape} \ntest shape => {test.shape}")
train_tokenized = [[token+"/"+POS for token, POS in tokenizer.pos(doc_)] for doc_ in train['document']]
test_tokenized = [[token+"/"+POS for token, POS in tokenizer.pos(doc_)] for doc_ in test['document']]
exclusion_tags = ['JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ', 'JX', 'JC',
'SF', 'SP', 'SS', 'SE', 'SO', 'EF', 'EP', 'EC', 'ETN', 'ETM',
'XSN', 'XSV', 'XSA']
f = lambda x: x in exclusion_tags
X_train = []
for i in range(len(train_tokenized)):
temp = []
for j in range(len(train_tokenized[i])):
if f(train_tokenized[i][j].split('/')[1]) is False:
temp.append(train_tokenized[i][j].split('/')[0])
X_train.append(temp)
X_test = []
for i in range(len(test_tokenized)):
temp = []
for j in range(len(test_tokenized[i])):
if f(test_tokenized[i][j].split('/')[1]) is False:
temp.append(test_tokenized[i][j].split('/')[0])
X_test.append(temp)
words = np.concatenate(X_train).tolist()
counter = Counter(words)
counter = counter.most_common(30000-4)
vocab = ['<PAD>', '<BOS>', '<UNK>', '<UNUSED>'] + [key for key, _ in counter]
word_to_index = {word:index for index, word in enumerate(vocab)}
def wordlist_to_indexlist(wordlist):
return [word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in wordlist]
X_train = list(map(wordlist_to_indexlist, X_train))
X_test = list(map(wordlist_to_indexlist, X_test))
return X_train, np.array(list(train['label'])), X_test, np.array(list(test['label'])), word_to_indexX_train, y_train, X_test, y_test, word_to_index = preprocess(train, test)index_to_word = {index:word for word, index in word_to_index.items()}
KoNLPy의 Komoran() 형태소 분석기를 사용했습니다.
drop_duplicates()를 통해 document 컬럼의 중복 값을 제거하는 코드를 작성했습니다.
이후, dropna()를 통해 위에서 확인할 수 있었던 결측 값을 제거했습니다.
형태소 분석기의 pos()를 사용해 품사 태깅을 진행했습니다.
품사 태깅과 함께 KoNLPy의 documentation을 통해 exclusion_tags를 설정하고 불용어 제거 과정을 진행했습니다. (조사, 구두점, 마침표, 접미사 등의 표현을 불용어로 처리했습니다.)
불용어 처리까지 완료한 훈련 데이터의 토큰들을 모아 Counter를 사용해 빈도순을 기준으로 30000개의 토큰을 구축했습니다.
마지막으로 train, test 토큰화 데이터에 대해 구축한 단어 사전을 기반으로 인덱스화를 진행했습니다.
In [14] :
all_data = list(X_train)+list(X_test)
num_tokens = [len(tokens) for tokens in all_data]
num_tokens = np.array(num_tokens)
# 평균값, 최댓값, 표준편차
print(f"토큰 길이 평균: {np.mean(num_tokens)}")
print(f"토큰 길이 최대: {np.max(num_tokens)}")
print(f"토큰 길이 표준편차: {np.std(num_tokens)}")
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print(f'설정 최대 길이: {maxlen}')
print(f'전체 문장의 {np.sum(num_tokens < max_tokens) / len(num_tokens)}%가 설정값인 {maxlen}에 포함됩니다.')
In [15] :
X_train = tf.keras.preprocessing.sequence.pad_sequences(X_train,
padding='pre',
value=word_to_index["<PAD>"],
maxlen=70)
X_test = tf.keras.preprocessing.sequence.pad_sequences(X_test,
padding='pre',
value=word_to_index["<PAD>"],
maxlen=70)
14, 15행은 적절한 토큰 최대 길이를 설정하고 패딩까지 진행하는 부분입니다.
pad_sequences를 통해 설정한 길이로 패딩을 진행합니다.
계산한 값이 아닌 임의의 값(70)을 지정하고 진행했습니다.
모델링 (LSTM)
In [17] :
vocab_size = 30000
word_vector_dim = 16
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(tf.keras.layers.LSTM(units=8))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
케라스의 Sequential 모델로 구성했습니다.
앞서 구축한 30000개의 토큰으로 구성된 단어 사전으로 Embedding layer을 구성하고
LSTM layer를 활용해 모델을 만들었습니다.
0과 1의 이진 분류이기 때문에 sigmoid를 활성화 함수로 사용했으며, 손실 함수는 binary_crossentropy를 사용했습니다.
성능 측정은 정확도로 진행했습니다.
단어 벡터 차원(word_vector_dim)과 LSTM layer의 units는 임의로 조정이 가능한 하이퍼파라미터 값입니다.
In [18] :
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, shuffle=True,
stratify=y_train, random_state=777)사이킷런의 train_test_split을 활용해 train데이터에서 일부 검증 데이터셋을 만들었습니다.
In[19] :
history = model.fit(X_train, y_train, epochs=10, batch_size=512,
validation_data=(X_val, y_val), verbose=1)
train 데이터에 대한 모델 훈련 과정입니다.
epoch, batch_size 값을 적절하게 조정할 수 있습니다.
In [20] :
predict = model.evaluate(X_test, y_test, verbose=1)
print(predict)
test 데이터에 대해 학습한 모델로 평가를 진행했습니다.
loss값과 accuracy값이 출력됩니다.
In [21] :
history_dict = history.history
print(history_dict.keys())
In [22] :
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()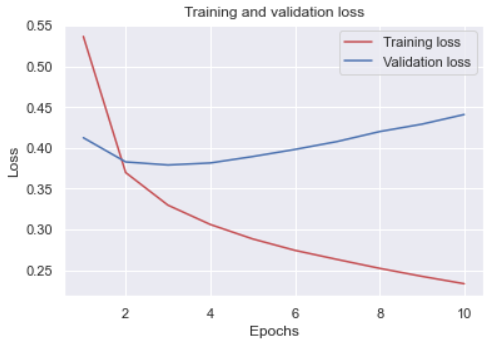
모델 훈련 중 각 에포크에 대한 train loss 값과 validation loss 값의 변화를 시각화한 코드입니다.
Stacked LSTM
2개의 LSTM Layer를 활용해 모델링을 진행한 부분입니다.
위의 모델링 과정과 유사하기 때문에 깃허브 페이지에서 확인 부탁드립니다.
'머신러닝 & 딥러닝 > 자연어처리' 카테고리의 다른 글
| [NLP] 도서 자료 텍스트 요약(Text Summarization) - TextRank (use gensim) (0) | 2022.06.30 |
|---|---|
| [NLP] 네이버 영화 리뷰 데이터(nsmc) 감성 분석 - CNN (0) | 2022.06.30 |
| [자연어 처리/NLP기초] 6. 벡터간 유사도 구하기: 코사인 유사도 (0) | 2022.02.23 |
| [자연어 처리/NLP기초] 5. 통계 기반 기법: 동시발생 행렬 (0) | 2022.02.21 |
| [자연어 처리/NLP기초] 4. 단어의 분산 표현과 분포 가설 (2) | 2022.02.21 |



댓글