NLP Tutorial
https://github.com/Seokii/Korean_NLP_Tutorial
GitHub - Seokii/Korean_NLP_Tutorial: 한국어 자연어처리 튜토리얼
한국어 자연어처리 튜토리얼. Contribute to Seokii/Korean_NLP_Tutorial development by creating an account on GitHub.
github.com
자연어처리를 공부하며 여러 한국어 NLP Task에 대한 예시 코드를 작성하고자 만들었습니다.
예시 코드를 통해 저와 같은 자연어처리 입문자들에게 도움이 되었으면 합니다 :)
해당 깃허브 주소를 통해 작성한 주피터 노트북 파일을 다운받거나 확인할 수 있습니다.
Dataset & Pre-trained model
Dataset
Hugging Face - KLUE : https://huggingface.co/datasets/klue
klue · Datasets at Hugging Face
Dataset Card for KLUE Dataset Summary KLUE is a collection of 8 tasks to evaluate natural language understanding capability of Korean language models. We delibrately select the 8 tasks, which are Topic Classification, Semantic Textual Similarity, Natural L
huggingface.co
- Hugging face의 KLUE-nli 데이터셋을 사용해 실습을 진행했습니다.
Pre-trained model
KoELECTRA model : https://github.com/monologg/KoELECTRA
GitHub - monologg/KoELECTRA: Pretrained ELECTRA Model for Korean
Pretrained ELECTRA Model for Korean. Contribute to monologg/KoELECTRA development by creating an account on GitHub.
github.com
- 해당 깃허브의 사전 학습 모델을 사용해 실습을 진행했습니다.
Jupyter Notebook
Load Dataset
import datasets
from datasets import load_dataset, load_metric, ClassLabel, Sequence
task = "nli"
datasets = load_dataset("klue", task)- datasets 라이브러리를 통해, Hugging Face의 데이터셋을 다운받을 수 있었습니다.
- 데이터셋을 정상적으로 불러온 뒤 확인했습니다.

- 데이터는 훈련 데이터 24,998개와 검증 데이터 3,000개로 구성되어있습니다.
- 훈련 데이터에서 따로 검증 데이터를 분리해 훈련을 진행했고,
라벨링이 되어 있는 검증 데이터를 테스트 데이터로 가정하고 실습을 진행했습니다.
EDA

- 결측치(null 값)를 확인했으나 존재하지 않아 제거할 필요가 없었습니다.
sns.set_theme(style="darkgrid")
ax = sns.countplot(x="label", data=train)labels, frequencies = np.unique(train.label.values, return_counts=True)
plt.figure(figsize=(5,5))
plt.pie(frequencies, labels = labels, autopct= '%1.1f%%')
plt.show()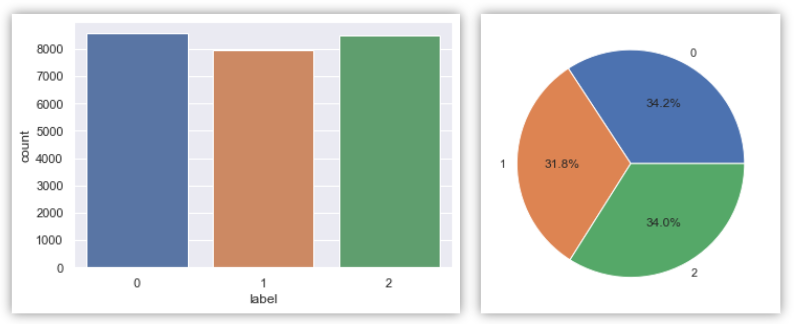
- 클래스 불균형을 확인하기 위해서 시각화를 진행했습니다.
- 클래스의 비율이 일정한 것을 확인할 수 있습니다.
Modeling

- 사전 훈련된 토크나이저를 통해 토크나이징과 인코딩을 진행한 후, 각 문장들의 토큰 수를 시각화 했습니다.

- 토큰 길이의 평균, 최대, 표준편차를 계산했습니다.
- 최대 길이는 98이며, 테스트 데이터셋에 대해서는 최대 길이가 88이 나왔습니다.
- 테스트 데이터는 최종 예측을 진행할 데이터로써 삭제 불가능한 데이터이기 때문에, 88 이상이어야 합니다. 따라서 90으로 패딩 값 설정하고 진행했습니다.
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s) <= max_len):
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))))

- 토큰 길이가 90이상인 데이터에 대해 삭제를 진행한 후의 결과입니다.
(삭제 진행 코드는 깃허브 참고)
def model_KoELECTRA():
with strategy.scope():
encoder = TFElectraModel.from_pretrained("monologg/koelectra-base-v3-discriminator", from_pt=True)
input_layer = Input(shape=(90,), dtype=tf.int32, name="input_layer")
sequence_output = encoder(input_layer)[0]
cls_token = sequence_output[:, 0, :]
output_layer = Dense(3, activation='softmax')(cls_token)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(Adam(lr=1e-5), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
- 사전 학습된 모델 불러와 모델 구조를 정의했습니다. 사진은 모델 요약 코드에 대한 결과입니다.

- 정의한 모델을 통해 학습 데이터를 통해 모델 학습을 진행했습니다.
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
- 모델 학습 동안의 train, test 데이터에 대한 loss값의 변화를 나타낸 시각화 결과입니다.
pred = model.predict(test_dataset, verbose=1)
pred_arg = pred.argmax(axis=1)
- 최종 결과를 확인하기 위해 테스트 데이터에 대해 예측을 수행했습니다.

- 테스트 데이터에 대해 0.856의 정확도가 산출됨을 확인했습니다.
'머신러닝 & 딥러닝 > 자연어처리' 카테고리의 다른 글
| 대학교 AI 질의응답 챗봇 만들기 - 5. 엑셀 내용 임베딩 및 pt파일 저장 & 입력 질문과 유사도 비교(코사인 유사도) (1) | 2022.07.29 |
|---|---|
| 대학교 AI 질의응답 챗봇 만들기 - 4. 질의응답 데이터 엑셀로 구축 (1) | 2022.07.29 |
| 대학교 AI 질의응답 챗봇 만들기 - 3. 의도 분류 모델(CNN) (0) | 2022.07.23 |
| 대학교 AI 질의응답 챗봇 만들기 - 2. 단어 사전 구축 (2) | 2022.07.22 |
| 대학교 AI 질의응답 챗봇 만들기 - 1. 사용 데이터 & 텍스트 전처리기 (1) | 2022.07.21 |




댓글