0. 프로젝트 소개 글 (포스팅 목록)
https://seokii.tistory.com/146
[Project] 대학교 AI 질의응답 챗봇 만들기
1. GitHub https://github.com/Seokii/Chatbot4Univ GitHub - Seokii/Chatbot4Univ: 대학교 재학생을 위한 AI 질의응답 챗봇 대학교 재학생을 위한 AI 질의응답 챗봇. Contribute to Seokii/Chatbot4Univ development by creating an account o
seokii.tistory.com
1. GitHub
(깃허브 스타 버튼 눌러주시면 글 작성에 큰 도움이 됩니다!)
https://github.com/Seokii/Chatbot4Univ
GitHub - Seokii/Chatbot4Univ: 대학생을 위한 AI 질의응답 챗봇 만들기
대학생을 위한 AI 질의응답 챗봇 만들기. Contribute to Seokii/Chatbot4Univ development by creating an account on GitHub.
github.com
2. 사용 데이터
챗봇 만들기에 사용될 데이터는 다음과 같습니다.
1. 네이버 영화 리뷰 데이터
GitHub - e9t/nsmc: Naver sentiment movie corpus
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com
네이버 영화 리뷰 데이터에 대한 감성 분류가 라벨링된 텍스트 데이터입니다.
2. AI Hub
AI-Hub
AI 허브 데이터 검색 추천검색어
aihub.or.kr
AI Hub 홈페이지에서 아래 목록의 데이터셋을 사용해 프로젝트를 진행했습니다.
- 일반 상식 데이터셋
- 용도별 목적 대화 데이터셋
- 주제별 텍스트 일상 대화 데이터셋
3. 데이터 처리
네이버 영화 리뷰 데이터셋은 텍스트 파일이며, AI Hub의 각종 데이터셋은 json의 형태로 제공됩니다.
데이터셋을 pandas를 사용해 데이터프레임으로 정리하고 csv 파일로 변환하는 작업을 진행했습니다.
프로젝트 파일에서 원본데이터 폴더와 변환데이터 폴더에 파일을 구분하여 저장했습니다.


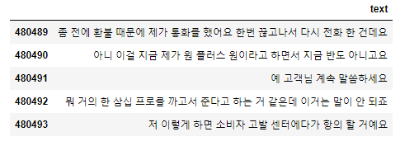
코드 참고 : https://github.com/Seokii/Chatbot4Univ/blob/main/utils/Data_to_csv.ipynb
4. 텍스트 전처리
챗봇 사용자에게 문장을 입력 받고 챗봇 엔진을 통해 답변을 출력해 전달하기 위해서는
입력 받은 문장과 구성하고 있는 문장들에 대한 텍스트 전처리 과정이 필요합니다.
입력 받은 문장을 토크나이저를 통해 품사별로 POS태깅을 진행한 후 지정한 불용어를 제거하는 작업을 구현했습니다.
아래 게시글은 한국어 형태소 토크나이저에 대한 기본적인 예시입니다.
NLP 기초 - KoNLPy를 활용한 한국어 형태소 토크나이징(Komoran, Kkma, Okt)
토크나이징(tokenizing) 일반적으로, 자연어 처리를 하기 위해서는 문장을 일정 의미를 지닌 작은 단어들로 나누어야 합니다. 가장 기본이 되는 단어를 토큰(token)이라 합니다. 말뭉치(혹은 문장)가
seokii.tistory.com
# utils/Preprocess.py
from konlpy.tag import Komoran
import pickle
class Preprocess:
def __init__(self, userdic=None): # userdic 인자에는 사용자 정의 사전 파일 경로 입력가능
# 형태소 분석기 초기화
self.komoran = Komoran(userdic=userdic)
# 제외할 품사
# 참조 : https://docs.komoran.kr/firststep/postypes.html
self.exclusion_tags = [
'JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ',
# 주격조사, 보격조사, 관형격조사, 목적격조사, 부사격조사, 호격조사, 인용격조사
'JX', 'JC',
# 보조사, 접속조사
'SF', 'SP', 'SS', 'SE', 'SO',
# 마침표,물음표,느낌표(SF), 쉼표,가운뎃점,콜론,빗금(SP), 따옴표,괄호표,줄표(SS), 줄임표(SE), 붙임표(물결,숨김,빠짐)(SO)
'EP', 'EF', 'EC', 'ETN', 'ETM',
# 선어말어미, 종결어미, 연결어미, 명사형전성어미, 관형형전성어미
'XSN', 'XSV', 'XSA'
# 명사파생접미사, 동사파생접미사, 형용사파생접미사
]
# Komoran POS tagging
def pos(self, sentence):
return self.komoran.pos(sentence)
# 불용어 제거
def get_keywords(self, pos, without_tag=False):
f = lambda x: x in self.exclusion_tags
word_list = []
for p in pos:
if f(p[1]) is False:
word_list.append(p if without_tag is False else p[0])
return word_list
5. 텍스트 전처리 테스트
# test/preprocess_test.py
from utils.Preprocess import Preprocess
sent = "컴공 과사 번호를 알려줘?...!"
# 전처리 객체 생성
p = Preprocess(userdic='../utils/user_dic.tsv')
# 형태소 분석기 실행
pos = p.pos(sent)
# 품사 태그와 같이 키워드 출력
ret = p.get_keywords(pos, without_tag=False)
print(ret)
# 품사 태그 없이 키워드 출력
ret = p.get_keywords(pos, without_tag=True)
print(ret)
전처리가 잘 진행되는지 테스트하는 코드입니다.
작성한 텍스트 전처리기 코드를 불러와 pos 태깅과 불용어 처리를 수행하고 결과를 출력했습니다.
'컴공', '과사'와 같은 단어는 사용자 사전을 지정하여 고유 명사로 인식하도록 .tsv파일을 작성해 지정해주었습니다.
'머신러닝 & 딥러닝 > 자연어처리' 카테고리의 다른 글
| 대학교 AI 질의응답 챗봇 만들기 - 3. 의도 분류 모델(CNN) (0) | 2022.07.23 |
|---|---|
| 대학교 AI 질의응답 챗봇 만들기 - 2. 단어 사전 구축 (2) | 2022.07.22 |
| [NLP] 도서 자료 텍스트 요약(Text Summarization) - TextRank (use gensim) (0) | 2022.06.30 |
| [NLP] 네이버 영화 리뷰 데이터(nsmc) 감성 분석 - CNN (0) | 2022.06.30 |
| [NLP] 네이버 영화 리뷰 데이터(nsmc) 감성 분석 - LSTM (2) | 2022.06.21 |




댓글