GitHub
쿠브플로우 관련 코드 내용은 GitHub에서 관리하고 있습니다.
https://github.com/Seokii/Study-MLOps
GitHub - Seokii/Study-MLOps: Study MLOps with Kubeflow
Study MLOps with Kubeflow. Contribute to Seokii/Study-MLOps development by creating an account on GitHub.
github.com
카티브 개념 이해와 설치하기
카티브에 대한 개념 설명은 이전 글을 참고바랍니다.
https://seokii.tistory.com/208
[Kubeflow] 쿠브플로우 카티브(Katib) 개념 이해와 설치하기
1. Documentation https://www.kubeflow.org/docs/components/katib/ Katib Documentation for Kubeflow Katib www.kubeflow.org 쿠브플로우 카티브에 대한 공식 문서입니다. 쿠브플로우에 대한 자료가 많이 없어서, 공식 문서를 참
seokii.tistory.com
1. Katib Doc
https://www.kubeflow.org/docs/components/katib/
Katib
Documentation for Kubeflow Katib
www.kubeflow.org
쿠브플로우 Katib의 공식 문서입니다.
카티브의 공식 문서를 참고해 글을 작성했습니다.
2. Katib Tutorial
공식 문서의 안내를 차례차례 따라해보겠습니다.
curl https://raw.githubusercontent.com/kubeflow/katib/master/examples/v1beta1/kubeflow-training-operator/tfjob-mnist-with-summaries.yaml --output tfjob-mnist-with-summaries.yaml
위의 명령어를 통해 작업이 정의된 .yaml 파일을 다운받습니다.
저는 study_katib라는 폴더를 만들고 저장했습니다.

yaml 파일에 정의된 작업 내용에서 다음과 같이 수정합니다.
1. 메타데이터에서 네임스페이스 부분을 자신의 kubeflow 네임스페이스로 변경합니다.
저는 기존 kubeflow에서 kubeflow-user-example-com으로 수정했습니다.
2. trialSpec > Worker > template 부분에 메타데이터에 대한 내용을 작성합니다.
공식 문서에 의하면 istio와 함께 쿠브플로우를 사용한다면, istio sidecar injection으로 인해 카티브에서 정의한 experiment가 동작하지 않는다고 설명되어있습니다. 해당 문제를 해결하기 위한 방법으로 sidecar injection에 대한 옵션을 false로 지정해야 작동함을 확인할 수 있었습니다.
kubectl apply -f tfjob-mnist-with-summaries.yaml그 후, 정의한 experiment 내용을 kubectl을 통해 작업을 생성하고 진행할 수 있습니다.
kubectl -n kubeflow-user-example-com get experiment tfjob-mnist-with-summaries -o yaml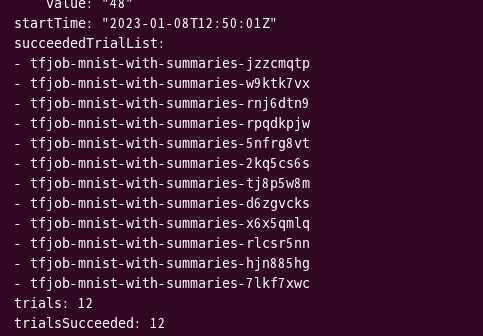
kubectl을 통해 현재 작업 상태 또한 확인할 수 있습니다.
저는 이미 12개의 trial이 모두 완료된 것을 확인할 수 있었습니다.
kubectl port-forward --address 0.0.0.0 svc/istio-ingressgateway -n istio-system 8080:80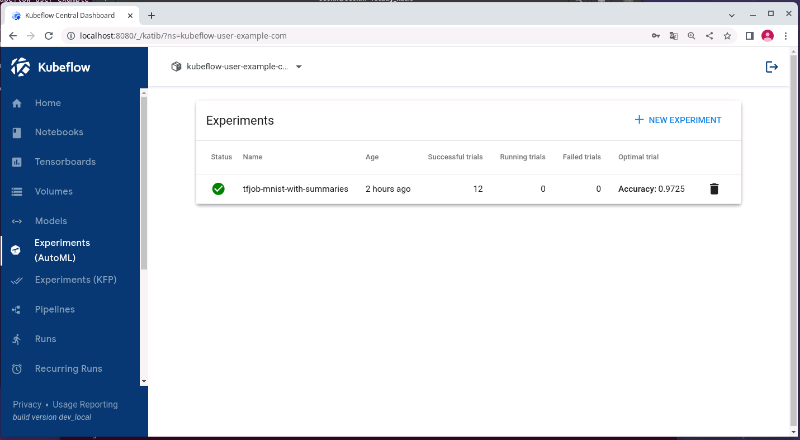
포트 포워드를 통해 쿠브플로우 대시보드를 접속 후 Experiments 메뉴로 들어가면,
카티브를 통해 생성된 Experiment를 확인할 수 있습니다.

생성한 실험의 이름과 함께 성공한 trial의 횟수와 가장 최적화된 trail의 지표 결과가 보여집니다.

이름을 눌러 해당 실험에 들어가면 하이퍼 파라미터에 따른 내용을 시각화해서 볼 수 있으며,

Overview 탭에서 해당 실험의 전반적인 내용들과

Trials 탭에서는 Trial별로 내용을 조회할 수 있습니다.
Trial에서 선택해 들어가면 더 세부적인 시각화와 정보 또한 확인할 수 있습니다.
그 밖에도 Details, YAML 메뉴를 통해
실험의 세부 정보(목적, 파라미터 종류, 알고리즘 종류 등)와
YAML 파일의 내용을 확인할 수 있습니다.
3. YAML 파일 살펴보기
이미 정의된 yaml 파일을 가져다 쿠브플로우에 전달하고
카티브를 통해 하이퍼 파라미터 튜닝을 해봤는데,
yaml 파일을 살펴보고 어떻게 작업을 정의하는지 알아보겠습니다.
먼저, yaml 파일의 전체 내용입니다.
---
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
namespace: kubeflow-user-example-com
name: tfjob-mnist-with-summaries
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy
algorithm:
algorithmName: random
metricsCollectorSpec:
source:
fileSystemPath:
path: /mnist-with-summaries-logs/test
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: batch_size
parameterType: int
feasibleSpace:
min: "32"
max: "64"
trialTemplate:
primaryContainerName: tensorflow
# In this example we can collect metrics only from the Worker pods.
primaryPodLabels:
training.kubeflow.org/replica-type: worker
trialParameters:
- name: learningRate
description: Learning rate for the training model
reference: learning_rate
- name: batchSize
description: Batch Size
reference: batch_size
trialSpec:
apiVersion: kubeflow.org/v1
kind: TFJob
spec:
tfReplicaSpecs:
Worker:
replicas: 2
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: docker.io/kubeflowkatib/tf-mnist-with-summaries:latest
command:
- "python"
- "/opt/tf-mnist-with-summaries/mnist.py"
- "--epochs=1"
- "--learning-rate=${trialParameters.learningRate}"
- "--batch-size=${trialParameters.batchSize}"
- "--log-path=/mnist-with-summaries-logs"
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
namespace: kubeflow-user-example-com
name: tfjob-mnist-with-summaries기본적으로 쿠브플로우 api 버전과 experiment임을, metadata로 네임스페이스를 정의합니다.
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy
algorithm:
algorithmName: random
metricsCollectorSpec:
source:
fileSystemPath:
path: /mnist-with-summaries-logs/test
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: batch_size
parameterType: int
feasibleSpace:
min: "32"
max: "64"그 후 spec을 통해 실험에 대한 다양한 옵션을 정의합니다. 내용은 다음과 같습니다.
- parallelTrialCount : 병렬로 실행할 Trial의 수입니다. 리소스가 허용하는 한도까지 실행합니다.
- maxTrialCount : 최대로 실행될 Trial의 수입니다.
- maxFailedTrialCount : Trial의 실패 한도 수입니다. 지정한 수만큼 실패하면 멈추게 됩니다.
- objective : 수집할 대상에 대한 metric을 설정합니다.
- type : 목표 지표의 최댓값, 최솟값 설정
- goal : 목표 수치
- objectiveMetricName : 평가 수치에 대한 이름(accuracy, validation-accuracy 등)
- additionalMetricNames : 추가로 수집할 평가 수치에 대한 이름 (예시에는 없음)
- algorithm : 하이퍼파라미터를 탐색할 알고리즘을 설정합니다.
(그리드, 랜덤, 하이퍼밴드, 베이지안최적화가 있습니다.) - metricsCollectorSpec : 각 Trial에서 수집할 메트릭의 메트릭 컬렉터를 정의합니다.
(파일 메트릭 컬렉터, TensorFlowEvent, Custom type가 있으며 각각 정의할 내용이 다릅니다.) - parameters : 하이퍼파라미터 입력 값을 정의합니다.
- name : 모델이 받을 하이퍼파라미터 값
- parameterType : 파라미터 타입 (int, double, category)
- feasibleSpace : 연속된 범위의 값을 설정, 연속 값이 아닌 경우 리스트로 정의할 것
trialTemplate:
primaryContainerName: tensorflow
# In this example we can collect metrics only from the Worker pods.
primaryPodLabels:
training.kubeflow.org/replica-type: worker
trialParameters:
- name: learningRate
description: Learning rate for the training model
reference: learning_rate
- name: batchSize
description: Batch Size
reference: batch_size
trialSpec:
apiVersion: kubeflow.org/v1
kind: TFJob
spec:
tfReplicaSpecs:
Worker:
replicas: 2
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: docker.io/kubeflowkatib/tf-mnist-with-summaries:latest
command:
- "python"
- "/opt/tf-mnist-with-summaries/mnist.py"
- "--epochs=1"
- "--learning-rate=${trialParameters.learningRate}"
- "--batch-size=${trialParameters.batchSize}"
- "--log-path=/mnist-with-summaries-logs"Trial의 템플릿을 정의하는 부분입니다.
ML 트레이닝 코드가 패키징된 도커이미지를 사용해야 합니다.
그리고 모델의 하이퍼파라미터를 커맨드라인 인자값이나 환경변수로 설정할 수 있어야 합니다.
이번 내용에서는 정의된 yaml파일과 쿠브플로우에서 제공하는 ML 트레이닝 이미지를 통해
간단하게 카티브를 사용해 하이퍼 파라미터 작업을 진행했는데,
다음 글에서는 모델 훈련 코드를 직접 도커 이미지로 만들고
yaml파일로 작성해 구현해보는 내용을 다루도록 하겠습니다.
'MLOps' 카테고리의 다른 글
| [MLOps] 쿠브플로우 KServe 설치 및 알아보기 (0) | 2023.01.10 |
|---|---|
| [MLOps] 쿠브플로우 카티브(Katib) 하이퍼파라미터 튜닝(2) (0) | 2023.01.10 |
| [MLOps] 쿠브플로우 카티브(Katib) 개념 이해와 설치하기 (0) | 2023.01.08 |
| [MLOps] 쿠브플로우 페어링(Fairing) mnist 학습하기 (2) | 2023.01.07 |
| [MLOps] 쿠브플로우 페어링(Fairing) 개념 이해와 설치하기 (1) | 2023.01.05 |




댓글