GitHub
쿠브플로우 관련 코드 내용은 GitHub에서 관리하고 있습니다.
https://github.com/Seokii/Study-MLOps
GitHub - Seokii/Study-MLOps: Study MLOps with Kubeflow
Study MLOps with Kubeflow. Contribute to Seokii/Study-MLOps development by creating an account on GitHub.
github.com
이전 글
https://seokii.tistory.com/209
[Kubeflow] 쿠브플로우 카티브(Katib) 하이퍼파라미터 튜닝(1)
GitHub 쿠브플로우 관련 코드 내용은 GitHub에서 관리하고 있습니다. https://github.com/Seokii/Kubeflow_Tutorial_KR GitHub - Seokii/Kubeflow_Tutorial_KR: Study MLOps with Kubeflow Study MLOps with Kubeflow. Contribute to Seokii/Kubeflow_T
seokii.tistory.com
이전 글에서 이미 정의되어 있는 CRD(yaml 파일)를 통해 매우 간단하게 카티브에 잡을 던져주고,
tensorfow로 mnist 데이터에 대해 학습해봤습니다.
이번에는 모델을 학습하는 코드를 직접 도커 이미지로 바꾸고,
CRD를 작성해 최종적으로 카티브로 하이퍼파라미터 튜닝을 진행하도록 하겠습니다.
모델 학습 파일 작성하기
텐서플로우를 통해 mnist를 학습하는 코드를 작성했습니다.
# mnist-katib-random.py
import tensorflow as tf
import argparse
def train():
print("TensorFlow version: ", tf.__version__)
parser = argparse.ArgumentParser()
parser.add_argument('--learning_rate', default=0.01, type=float, required=False)
parser.add_argument('--dropout', default=0.2, type=float, required=False)
parser.add_argument('--opt', type=int, default=1, required=False)
args = parser.parse_args()
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(args.dropout),
tf.keras.layers.Dense(10, activation='softmax')
])
sgd = tf.keras.optimizers.SGD(learning_rate=args.learning_rate)
adam = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
optimizers = [sgd, adam]
model.compile(optimizer=optimizers[args.opt],
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
loss, acc = model.evaluate(x_test, y_test, batch_size=128)
print(f"model val-loss={loss:.4f} val-acc={acc:.4f}")
class KatibMetricLog(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print("\nEpoch {}".format(epoch + 1))
print("accuracy={:.4f}".format(logs['acc']))
print("loss={:.4f}".format(logs['loss']))
print("Validation-accuracy={:.4f}".format(logs['val_acc']))
print("Validation-loss={:.4f}".format(logs['val_loss']))
if __name__ == '__main__':
train()전체 코드 내용입니다. 중요한 부분만 잘라서 보겠습니다.
parser = argparse.ArgumentParser()
parser.add_argument('--learning_rate', default=0.01, type=float, required=False)
parser.add_argument('--dropout', default=0.2, type=float, required=False)
parser.add_argument('--opt', type=int, default=1, required=False)
args = parser.parse_args()argparse 라이브러리를 사용해 하이퍼 파라미터를 정의한 부분입니다.
카티브를 통해 learning rate, dropout, optimizer(리스트로 여러 개를 정의해서 튜닝)를
튜닝 하기 위해서 정의했으며, type과 default값 또한 설정했습니다.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(args.dropout),
tf.keras.layers.Dense(10, activation='softmax')
])위에서 argparse로 정의한 dropout을 모델 구조를 정의할 때, 튜닝할 수 있도록 사용했습니다.
( tf.keras.layers.Dropout(args.dropout) )
sgd = tf.keras.optimizers.SGD(learning_rate=args.learning_rate)
adam = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
optimizers = [sgd, adam]
model.compile(optimizer=optimizers[args.opt],
loss='sparse_categorical_crossentropy',
metrics=['acc'])예시에서는 SGD, Adam 두 가지의 옵티마이저를 정의하고 튜닝에 사용했습니다.
드롭아웃과 마찬가지로 model.compile의 optimizer 정의 부분에 같은 방식으로 정의했습니다.
training_history = model.fit(x_train, y_train,
verbose=0,
batch_size=64, epochs=5,
validation_data=(x_val, y_val),
callbacks=[KatibMetricLog()])
class KatibMetricLog(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
# RFC 3339
local_time = datetime.now(timezone.utc).astimezone().isoformat()
print("\\nEpoch {}".format(epoch + 1))
print("{} accuracy={:.4f}".format(local_time, logs['acc']))
print("{} loss={:.4f}".format(local_time, logs['loss']))
print("{} Validation-accuracy={:.4f}".format(local_time, logs['val_acc']))
print("{} Validation-loss={:.4f}".format(local_time, logs['val_loss']))
# 내용 수정 후
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))정의한 model을 학습하는 부분입니다.
학습할 때 콜백으로 정의한 KatibMetricLog를 받게 됩니다.
매 epoch마다 콜백으로 정의한 acc, loss, val-acc, val-loss 등을 확인할 수 있습니다.
(+내용추가)
yaml 파일을 정의하는 부분에서 metric collector를 정의하지 않았기 때문에
기본 값인 StdOut으로 설정됩니다.
따라서, 그냥 단순하게 print(f"model val-loss={loss:.4f} val-acc={acc:.4f}") 의 내용처럼
'{} {}'의 형식으로 출력해주면 되기 때문에 콜백 적용을 빼고 코드를 수정했습니다.
컨테이너 이미지 만들기
# Dockerfile
FROM tensorflow/tensorflow:2.10.0
ADD mnist-katib-random.py /컨테이너 이미지를 만들기 위해서 Dockerfile을 생성했습니다.
docker build -t seokii/mnist-katib-random:0.0.1 .도커 허브에 이미지를 푸시하기 전, 명령어를 통해 빌드합니다.
docker push seokii/mnist-katib-random:0.0.1빌드한 도커 이미지를 도커 허브에 푸시합니다.

도커 허브에서 정상적으로 푸시되었음을 확인할 수 있었습니다.
Yaml 파일 생성하기
# katib-example.yaml
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
namespace: kubeflow-user-example-com
name: mnist-katib-random
spec:
objective:
type: maximize
goal: 0.99
objectiveMetricName: val-acc
additionalMetricNames:
- val-loss
algorithm:
algorithmName: random
parallelTrialCount: 3
maxTrialCount: 60
maxFailedTrialCount: 3
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.2"
- name: dropout
parameterType: double
feasibleSpace:
min: "0.1"
max: "0.5"
- name: opt
parameterType: int
feasibleSpace:
min: "0"
max: "1"
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: learning_rate
description: Learning Rate for modeling training
reference: learning_rate
- name: dropout
description: dropout rate
reference: dropout
- name: opt
description: Optimizer for modeling training
reference: opt
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: training-container
image: seokii/mnist-katib-random:0.0.4
command:
- "python"
- "/mnist-katib-random.py"
- "--learning_rate=${trialParameters.learning_rate}"
- "--dropout=${trialParameters.dropout}"
- "--opt=${trialParameters.opt}"
restartPolicy: Never필요한 내용에 따라 CRD를 yaml으로 정의했습니다.
CRD에 대한 상세한 설명은 쿠브플로우 카티브(Katib) 하이퍼파라미터 튜닝(1) 를 참고바랍니다.
Pod 생성과 하이퍼 파라미터 튜닝
kubectl apply -f katib-example.yaml
kubectl 명령어를 통해 카티브에 작업을 던져주고, 하이퍼파라미터 튜닝을 진행할 수 있습니다.
kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
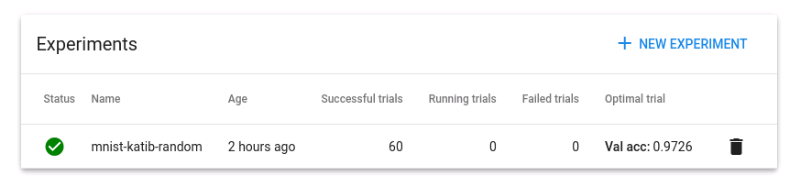
포트 포워딩후 대시보드에서 Experiment로 들어가면, 생성한 카티브 작업이 진행되고 있음을 확인할 수 있습니다. (예시 사진은 이미 직압이 끝나고 캡쳐했습니다.)
간단한 결과 분석
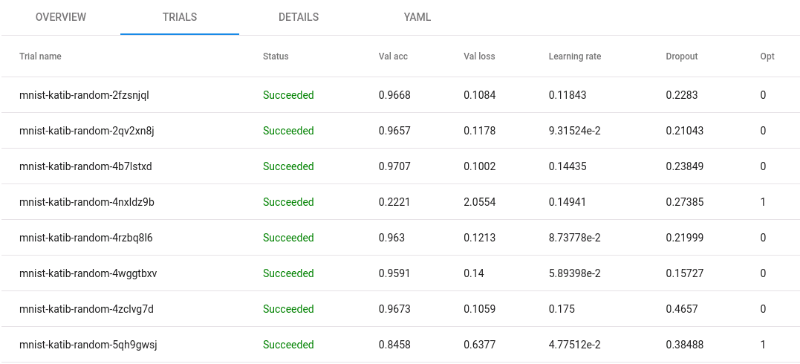
maxTrialCount을 60으로 설정했었고, 60번의 작업횟수에 도달 해 작업이 완료되었습니다.
trials에서 각 trial별 결과 값과 하이퍼 파라미터 값들을 확인할 수 있었습니다.
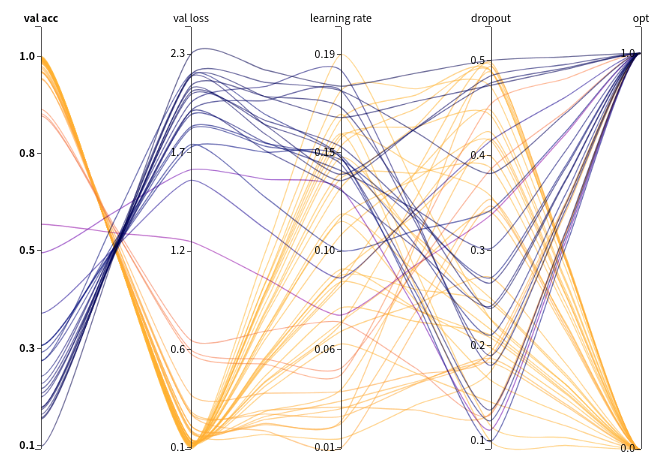
시각화 부분을 살펴보면,
성능이 좋았을 때(val_acc가 높고 val_loss 낮은 경우)는 Optimizer가 SGD인 경우(opt[0])였습니다.
SGD가 opt[1]인 Adam보다 성능이 상대적으로 좋았던 것을 확인할 수 있었습니다.
'MLOps' 카테고리의 다른 글
| [MLOps] 쿠브플로우 KServe 모델 배포하기 (0) | 2023.01.12 |
|---|---|
| [MLOps] 쿠브플로우 KServe 설치 및 알아보기 (0) | 2023.01.10 |
| [MLOps] 쿠브플로우 카티브(Katib) 하이퍼파라미터 튜닝(1) (0) | 2023.01.09 |
| [MLOps] 쿠브플로우 카티브(Katib) 개념 이해와 설치하기 (0) | 2023.01.08 |
| [MLOps] 쿠브플로우 페어링(Fairing) mnist 학습하기 (2) | 2023.01.07 |




댓글