GitHub
MLOps 및 Kubeflow 관련 코드 내용은 GitHub에서 관리하고 있습니다.
https://github.com/Seokii/Study-MLOps
GitHub - Seokii/Study-MLOps: Study MLOps with Kubeflow
Study MLOps with Kubeflow. Contribute to Seokii/Study-MLOps development by creating an account on GitHub.
github.com
참고사이트 : 모두의 MLOps
(쿠브플로우 공부에 많은 도움이 된 사이트입니다!)
파이프라인 코드
from kfp.components import InputPath, OutputPath, create_component_from_func
from kfp.dsl import pipeline
from functools import partial
import kfp
@partial(
create_component_from_func,
packages_to_install = ["pandas", "dill", "scikit-learn==1.0.1"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
@partial(
create_component_from_func,
packages_to_install = ["pandas", "dill", "scikit-learn==1.0.1"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
@pipeline(name="complex_pipeline")
def complex_pipeline(kernel: str):
iris_data = load_iris_data()
model = train_from_csv(
train_data = iris_data.outputs["data"],
train_target = iris_data.outputs["target"],
kernel = kernel,
)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(complex_pipeline, "complex_pipeline.yaml")
# 데이터프레임, 모델과 같은 복잡한 객체의 타입은 어떻게 입력해야 하나?
이전 글인 파이프라인 컴포넌트 생성하기에서 인자, 반환 값들에 대한 타입에 대한 입력이 필요했습니다.
그러나, 쿠브플로우에서는 각 컴포넌트들이 메모리를 공유하지 않기 때문에 모델이나 데이터프레임과 같은 복잡한 객체들은 json의 형식이 아니면 전달하기 어렵습니다.
이를 해결하기 위한 방법으로 InputPath, OutputPath 기능을 쿠브플로우에서 제공합니다.
# InputPath, OutputPath
InputPath는 입력 경로, OutputPath는 출력 경로를 의미합니다.
위의 코드에서 기존의 타입 힌트를 지정하는 과정에서
InputPath("출력 포맷")의 형태로 선언해 사용할 수 있습니다.
입력 혹은 출력의 포맷이 일정하지 않다면 선언하지 않아도 됩니다.
한 가지 주의할 점은, 아래의 파이프라인을 정의하는 부분입니다.
iris_data = load_iris_data()
train_data=iris_data.outputs["data"],
train_target=iris_data.outputs["target"],기존 컴포넌트 작성 부분에서는 data_path, target_path로 선언을 했지만,
파이프라인 코드의 load_iris_data 컴포넌트에서 출력을 입력 받는 부분에서는
.outputs["data_path"] 또는 .outputs["target_path"]가 아닌 단순히 "data", "target"으로 지정했습니다.
이것은 쿠브플로우에서 정한 법칙으로 InputPath 와 OutputPath 으로 생성된 경로들은 파이프라인에서 접근할 때 _path 접미사를 생략하여 접근합니다.
# functools.partial 사용
파이프라인에서 컴포넌트가 원활하게 동작하게 하기 위해서
각 컴포넌트에서 사용할 패키지들에 대한 추가가 필요합니다.
functools에서 제공하는 partial을 사용해 packages_to_install 인자를 정의해 코드에서 사용한 모듈, 패키지를 추가할 수 있습니다.
Runs 결과

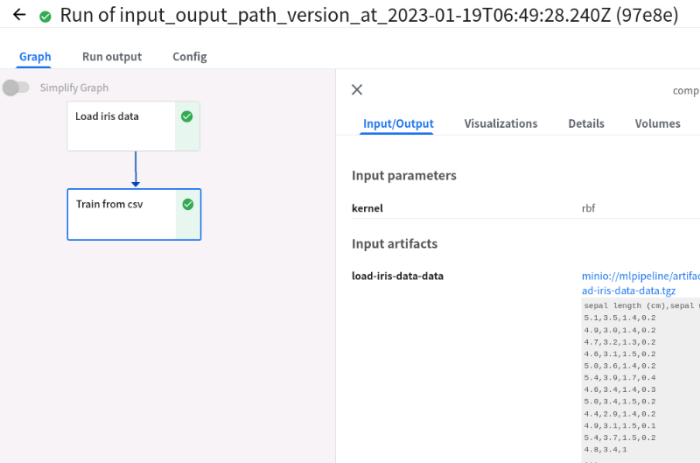
생성된 yaml파일을 통해 파이프라인을 만들었고,
Create run을 통해 run을 생성하여 파이프라인을 실행한 결과입니다.
'MLOps' 카테고리의 다른 글
| [MLOps] 쿠브플로우 주피터 노트북 서버 - 커스텀 이미지 사용 (0) | 2023.01.19 |
|---|---|
| [MLOps] 쿠버네티스에 MLflow 설치하기 (1) | 2023.01.17 |
| [MLOps] 쿠브플로우 파이프라인 - 실행(Run) (0) | 2023.01.17 |
| [MLOps] 쿠브플로우 파이프라인 - yaml 파일 업로드 (0) | 2023.01.16 |
| [MLOps] 쿠브플로우 파이프라인 - 코드 작성 (0) | 2023.01.16 |




댓글