영어로 된 논문들은 읽고 이해하는데 시간이 오래 걸려
전국에 계신 여러 뛰어난 연구자분들이 저술한 국내 학술 논문들을 살펴보고 지식을 쌓아가면 좋겠다는 생각이 들어 https://seokii.tistory.com/108(공항 내 시설 안내 서비스를 위한 마커리스 한국 수어 인식 기술) 이 글을 시작으로 계속 국내의 학술 논문을 읽고 정리할 생각입니다.
이번에 읽고 공부한 논문은 제주도에서 쓰이는 제주어를 표준어로 바꾸는 방법을 제안한 논문입니다.
해당 논문은 창원대학교에서 발간한 논문입니다.
논문 링크 : "복사 매커니즘을 이용한 한국어-제주어 기계번역(창원대학교)"
요약(Abstract)

논문의 요약 부분입니다.
제주어와 한국어에 겹치는 어휘가 많다는 점에 주목해 포인트 생성 네트워크를 사용하고 보상을 적용한 방법론을 제시했다고 소개합니다. 또한 데이터의 출처와 BLEU Score를 기재했습니다.
서론(Introduction)
요약에서 언급한 것처럼, 한국어와 제주어 사이에는 같은 한글을 사용해 글자를 표기하기 때문에 겹치는 어휘가 상당히 많다고 주장했습니다.
논문에서는 그러한 점에 주목해 "Get to the point: Summarization with pointer-generator networks." 논문의 포인터 생성 네트워크를 복사 매커니즘으로 사용하고 목표 언어에 보상(reward)의 개념을 도입해 기계 번역을 수행했다고 합니다.
제안 방법(Proposed Approach)
구체적인 방법에 대한 내용을 설명한 부분입니다.
논문에서는 그림 1을 통해 모델의 구조를 제안합니다.
구조는 “AMR Parsing as Sequence-to-Graph Transduction”의 논문의 구조를 활용했다고 밝히며, 타겟 어텐션 분포 부분을 제외하였다고 합니다.
인코더 디코더 구조를 활용하고 토큰화, 임베딩(KorBERT), 양방향 및 단방향 LSTM, 바다나우 어텐션 등을 활용해 문맥 벡터(context vector)를 만들고 MLP(다층 퍼셉트론)과 지역 사전 및 전역 사전을 통해 문장을 생성합니다.
보상의 개념은 위의 식을 통해 진행되며,
상반 관계를 갖는 보상값이 커지면 손실 함수 값이 작아지는 구조입니다.
보상의 식인 (3)과 손실 함수 식인 (4)를 더해 최종 손실 함수(5)가 되며, 이 값을 통해 모델의 학습을 진행합니다.
데이터
어떤 데이터셋을 사용했는지 설명해주는 부분입니다.
해당 논문에서는 제주어 학습 데이터셋인 JIT(Jejueo Interview Transcripts)를 이용했습니다.
카카오 브레인에서 구축한 데이터로써, '한국어 문장-제주어 문장'으로 구성된 17만 개의 병렬 데이터셋입니다.
실험 및 분석(Experiments)
하이퍼 파라미터 구성, 각 구조에서의 은닉층 크기, 드롭아웃 수치, 옵티마이저 종류, 학습률 등등 실험을 진행하며 설정한 자세한 값들에 대한 내용이 설명되어있습니다.
또한, 성능 측정 방법은 BLEU Score로 진행했으며, 표를 통해 세부적인 내용을 확인할 수 있었습니다.
다음은 표3 모델 성능에 대한 내용입니다.
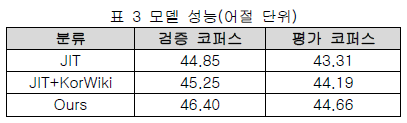
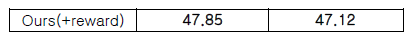
다음은 표4 실험의 정성평가 통계입니다.
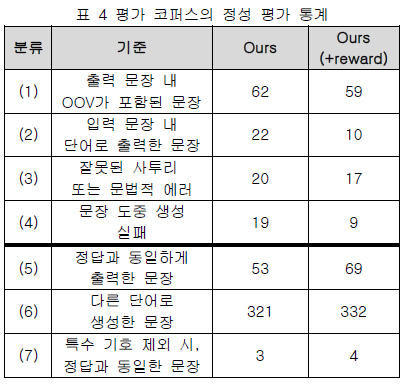
결론 및 향후 연구(Conclusion)


느낀 점
예전에 인터넷을 보면서 에브리타임 캡처 사진인데, 제주에서 온 학생들끼리 제주어로 소통하는 일종의 밈과 같은 짤을 본 적이 있다. 그 사진이 돌아다니면서 제주어를 잘 모르는 사람은 이해를 하지 못하고 제주도에서 오랫동안 거주했었던 사람들은 다 이해를 하며 그런 차이가 웃음 포인트였다.
같은 나라이지만 지역별 사투리가 존재해 한국어지만 서로 이해하지 못하는 경우가 종종 있다.
이런 것들을 기계 번역 분야에 적용해 연구를 했다는 것이 참 흥미로웠다.
제주어가 사라져갈 위기에 처했다는 뉴스 기사를 본 적이 있다. 해당 논문을 통해 제주어를 다른 사람들이 좀 더 잘 이해할 수 있게 하는 계기가 되며 자료 보존의 측면에서 매우 좋은 시도인 것 같다.
논문을 읽어 보며 내가 아직 모르는 개념도 많고, 추가적으로 읽어야 할 논문도 생겨서 앞으로 더 열심히 공부를 해야겠다.
기계 번역에 관심이 있는 사람들은 이 논문을 꼭 한 번 읽어봤으면 좋겠다.




댓글