얼마 전 카카오브레인의 KoGPT 소개영상을 본 적이 있습니다.
자연어 처리(NLP) 분야에 대해서는 공부를 한 적이 없었는데, 카카오브레인의 소개 영상을 보고 자연어 처리 분야에 대해서 관심이 생겼습니다. 해당 영상에서 GPT-3에 대해서 언급을 하는데 자연어 처리 분야에 대해서 본격적으로 공부하기 전에 GPT-3를 알고자 해당 논문을 찾게 되었습니다.
GPT-3 논문을 보기 전에 GPT-1 부터 차례대로 보려고 합니다.
논문 링크 : Improving Language Understanding by Generative Pre-Training
Introduction

논문에서는 원시 텍스트(raw text)에서 학습을 하는 효과적인 능력은 자연어 처리에서 지도 학습에 대한 의존성을 완화하는데 중요하다고 합니다.
그리고 대부분의 딥러닝 방법에는 상당한 양의 라벨링된 데이터가 필요하며, 이러한 데이터가 없는 상황에서는 라벨링이 없는 데이터를 활용할 수 있는 모델이 대안이 될 수 있고 이는 시간과 비용이 많이 들지만 상당한 성능 향상을 가져온다고 했습니다.

라벨링이 안된 데이터에서 단어 수준 이상으로는 정보를 활용하기가 어렵다며 두 가지 이유를 설명했습니다.
첫 번째는 어떤 유형의 최적화 목표(optimization objectives)가 텍스트 표현을 학습함에 있어 가장 효과적인지 불분명하다고 했습니다. 그리고 최근 연구에서는 language modeling, machine translation, discourse coherence 등 여러 가지의 연구 목표가 있으며 각각의 성능은 서로의 목표에서 더 뛰어나다고 합니다.
두 번째 이유로는 학습된 표현을 target task로 전달하는 효과적인 방법에 대한 합의(consensus)가 없다고 설명했습니다.

이 논문에서는 unsupervised pre-training 이라 불리우는 과정과 supervised fine-tuning 이라 불리우는 과정의 조합을 통해서 semi-supervised(준지도학습)의 접근법을 탐구한다고 합니다.
목표는 광범위한 task에서 최소한의 적응(adaptation)을 통해 전달되는 보편적인 표현을 학습하는 것입니다.
그 밑으로는 모델 구조의 설명, 평가 절차 등에 대해서 설명을 합니다.
그리고 그것들에 대한 장점에 대한 부가설명을 하고 있습니다.
마지막으로는 분야 별로 성능이 어느 정도 향상했는가에 대한 이야기를 하면서 introductoin을 마칩니다.
Related Work
Semi-supervised learning for NLP

해당 섹션에서는 논문에서의 연구가 NLP(자연어 처리)에 대해서 준지도학습(semi-supervised learning)의 범위에 폭넓게 포함된다고 말합니다.
이 패러다임은 sequence labeling이나 text classification과 같은 작업에 적용되면서 상당한 관심을 끌었으며, 초기 연구에서는 단어 수준이나 구문 수준의 통계를 계산(to compute word-level or phrase-level statistics)하기 위해서 사용했고 이 통계는 지도학습 모델에서 기능으로 사용되었다고 언급합니다.
그리고 지난 몇 년 동안 연구자들이 라벨링되지 않은 말뭉치(corpus)에 대해 학습된 word embedding을 사용해서 다양한 작업 성능을 향상 시킨것을 입증해왔지만 그것은 주로 단어 수준의 정보만을 전달하며 논문에서의 목적은 그 이상의 수준을 포착하는 것이 목표라고 언급했습니다.
Unsupervised pre-training

Unsupervised pre-training은 위에서 언급한 지도학습의 (최적화)목표를 수정하는 대신 좋은 초기점?(initialization point)을 찾는 것이 목표인 준지도 학습(semi-supervised learning)의 특별한 경우입니다.
초기의 연구는 이미지 분류와 회귀에서 이 기법의 사용을 탐구했고, 후속 연구에서는 정규화 체계로 작용해서 DNN(deep neural networks)의 더 나은 일반화를 가능하게 한다는 것을 입증했으며, 최근의 연구에서는 image classification, speech recognition, entity disambiguation, machine translation 등과 같은 다양한 작업에서 심층 신경망을 훈련시키는데 도움이 되게 사용했다고 합니다.


나머지 부분의 내용은 자신들의 모델을 사용했을 때와 아닐 때의 비교를 하며 설명합니다.
그리고 간단한 부가 설명이 포함되어있습니다.
Auxiliary training objectives

- auxiliary : 보조의, 예비의
auxiliary unsupervised training objectives를 추가하는 것은 준지도 학습의 대안 형태이다라고 논문에서 말합니다. 초기의 연구에서는 다양한 범위의 auxiliary NLP task 사용해 semantic role labeling을 향상시켰으며, 더 최근에 와서는 auxiliary language modeling objective를 그들의 target task obejkctive에 추가하면서 sequence labeling에 있어 성능 향상을 입증했다고 합니다.
그리고 논문에서의 실험에서도 auxiliary objective를 사용하지만, unsupervied pre-training은 이미 target task와 관련된 몇 가지 언어적 측면을 학습한다고 합니다.
Framework

Framework에 대한 간단한 설명을 하고 내용이 시작됩니다. 내용은 다음과 같습니다.
훈련 절차는 두 단계로 이루어져 있습니다.
첫 번째는, 대규모 텍스트 말뭉치에서 고용량의 언어 모델을 학습하는 것입니다.
다음은 fine-tuning 단계를 거쳐 라벨링된 데이터를 사용해서 모델을 dicriminative task에 적응시킵니다.
Unsupervised pre-training
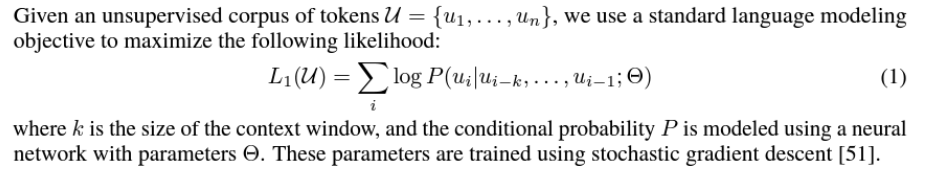
unsupervised pre-training에서는 토큰이 주어지면 표준의 language modeling 목적함수가 쓰이고 가능성을 최대화 시키려 한다고 합니다.
- \( k \)는 context window의 크기
- 조건부 확률 \( P \)는 매개변수 \( \Theta \)를 가진 신경망을 사용해 훈련됨
- 매개변수들은 경사 하강법을 사용해 훈련됨

논문의 실험에서 Transformer의 변형인 multi layuer Transformer dceoder를 언어모델에 사용하고,
이 모델은 multi-headed self-attention operation을 input token에 대해 적용해 target token에 대한 출력 분포를 생성한다고 합니다.
- \( U \) = (\( u_{-k} \) , ... , \( u_{-1} )\) 은 token에 대한 context vector
- \( n \) 은 레이어의 수
- \( W_{e} \) 는 token embedding matrix
- \( W_{p} \) 는 position embedding matrix
Supervised fine-tuning

앞 절의 unsupervised pre-training의 과정 이후 supervised fine-tuning 단계를 진행하게 됩니다.
labled된 dataset \( C \)를 가정하고, 각 인스턴스는 label \( y \) 와 함께 \( x^1 \), ... , \( x^m \) 와 같은 input token의 sequence로 이루어집니다.
input은 전 단계인 unsupervised pre-training 통해 전달되고 transformer 구조의 마지막 블록의 활성화 값 \( h_{l}^{m} \)을 얻게 됩니다. 그리고 y를 예측하기 위해 파라미터 \( W_{y} \)를 가진 추가된 linear ouput layer가 제공됩니다.
이를 통해 얻을 수 있는 목표 함수는 위와 같습니다. ( \( L_{2} \)(\( C \) = \( \Sigma_{\left(x, y\right)} logP(y|x^1, ... , x^m) \) )
이러한, fine-tuning 과정을 통해
(a) improving generalization of the supervised model,
(b) accelerating convergence
를 기대할 수 있습니다.

\( \lambda \)를 가중치(weight)로 두어 위와 같이 optimize(최적화) 한다고 합니다.
( Specifically, we optimize the following objective (with weight λ): )
전체적으로 fine-tuning 단계에서 필요한 추가 매개 변수는 \( W_{y} \) 와 delimiter token에 대한 embedding뿐이라고 설명합니다. (delimiter : 구분 기호)
아래의 섹션 3.3에서 설명을 하겠다고 적혀있습니다.

3.2.의 마지막에 해당 그림이 나옵니다.
왼쪽이 한 개의 Transformer 구조이며 12개를 사용한다고 표시했고,
오른쪽은 각각 다른 task들에 대해서 Pretrained model에 linear layer 추가해서 fine-tuning을 진행하는 과정입니다.
task에 따라서 앞의 token sequence 변환이 다른 것을 확인할 수 있습니다.
Task-specific input transformations

해당 섹션에서는 각각의 task에 대한 모델 구조에 대해서 설명해줍니다. (위의 사진 참고)

Textual entailment
- 전제(premise) \( p \)와 가설(hypothesis) \( h \) 토큰을 구분 기호 토큰($)와 연결
Similarity
- 유사성을 비교하는 작업에서는 두 문장의 고유한 순서가 없기 때문에 가능한 문장 순서(구분 기호 토큰 포함)를 모두 포함해 각각 독립적으로 처리하여 Linear layer 과정 전에 요소별로 추가된 두 개의 시퀀스 표현(sequence representations) \( h_{l}^{m} \) 을 생성
Question Answering and Commonsense Reasoning
- context document \( z \), question \( q \), 가능한 대답들의 집합인 {\( a_{k} \)} 가 주어집니다.
document context와 quesiton을 각각의 possible answer과 연결해 연결토큰을 추가하여 [\( z;q;$a_{k} \)]의 형태로 값을 얻습니다.
그 후 softmax를 통해 정규화시켜 가능한 답변에 output distribution을 제공합니다.
Experiments
Setup

Unsupervised pre-training
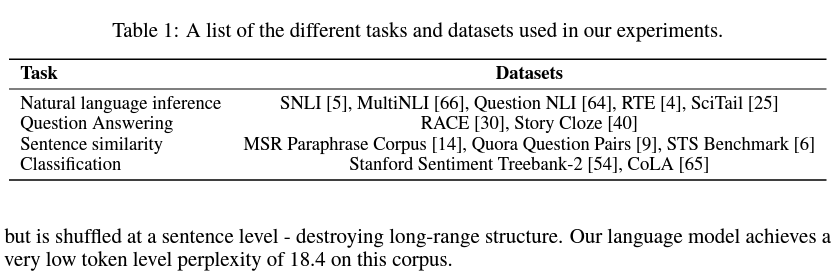
해당 논문에서 BooksCorpus 데이터셋을 사용해 언어 모델을 학습했다고 하며 이는 7000권 이상의 양이라고 합니다. 그리고 이 데이터셋에서는 긴 길이의 연속적인 텍스트가 포함되있어 위에서 말했던 long-range information을 학습할 수 있다고 했습니다.
ELMO와 비교를 하는데, ELMO도 거의 비슷한 크기의 데이터셋인 1B Word Benchmark를 사용하지만 논문에서 사용한 데이터셋만큼의 range의 구조를 가질수 없다고 주장합니다.
Model specifications

해당 섹션에서는 논문에서의 모델이 original transformer work의 과정을 거의 따랐다고 하며,
12개의 transformer decorder를 masked self-attention heads와 함께 학습했다고 합니다.
밑의 내용은 learning rate, epoch, layernorm, L2 regularization 과 같은 구체적인 수치에 대해서 설명을 하고 있습니다.
Fine-tuning details
해당 섹션에서도 fine-tuning 단계에서의 구체적인 수치에 대해 언급하고 있습니다.
Supervised fine-tuning.

위에서 언급했던 내용과 비슷합니다.
natural language inference, question answering, semantic similarity, text classification 을 포함한 작업에서의 연구를 진행했다고 합니다.
Natural Language Inference
NLI 즉, recognizing textual entailment라고도 알려져 있는 이 작업은 주어진 문장의 쌍을 읽고
entailment, contradiction, neutral 이 세가지의 상태를 판단하는 것입니다.
이 과정은 어휘적/구문적 모호성, 공동참조(coreference) 등 다양한 텍스트의 현상들 때문에 어려운 작업이라고 합니다.
SNLI, MNLI, QNLI, SciTail, RTE의 5개의 데이터셋에서 모델을 평가한다고 언급합니다.

그 후 표를 보여주며 GPT 모델의 성능을 다른 모델들과 비교하여 평가를 합니다.
자신들의 모델이 수치상으로 다른모델들과 비교했을 때 뛰어나며, 이는 언어적 모호성과 언급했던 현상들에 대해서 잘 처리할 수 있음을 보여준다고 말합니다.
Question answering and commonsense reasoning

이 섹션에서는 question answering and commonsense reasoning 이라는 task에서의 해당 모델의 성능 지표를 평가합니다.
평가를 하는 데이터셋은 RACE와 Story Cloze이며 이유는 해당 데이터셋이 다른 데이터셋 보다 더 많은 추론 유형 질문이 있으며, 이것이 논문에서의 모델이 추구하는 long-range context를 파악하는 능력을 평가하는데 적합하다고 판다을 했다고 합니다.
결과는 위의 표처럼 다른 모델들보다 뛰어남을 보였으며, 이를 통해 long-range context를 효과적으로 처리할 수 있다고 주장합니다.
Semantic Similarity
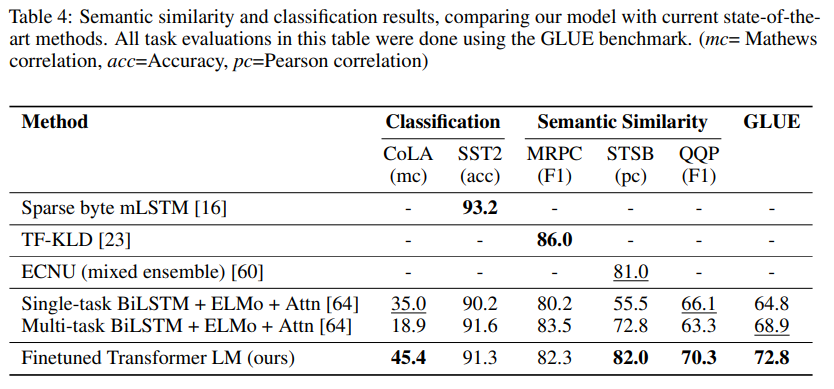
Semantic Similarity 과정은 두 문장이 주어졌을 때, 의미적으로 동일한지의 여부를 예측하는 것입니다.
challenge라고 불리울만한 요소들은 부정에 대한 이해도, 구문적 모호성 등이 있습니다.
이 과정에서는 MRC, Quora, STS-B 세 가지의 데이터셋을 사용했다고 합니다.
표를 통해 성능의 차이를 확인할 수 있습니다.
Classification
마지막으로 classification task입니다. 이 과정은 크게 두 가지의 다른 task로 진행이 됩니다.
CoLA 데이터셋에서는 주어진 문장이 문법적으로 맞았는지 틀렸는지 판단을 하는 task가 수행하며,
SST-2 데이터셋에서는 주어진 문장에 대해서 긍정, 부정을 판단하는 binary classification를 수행합니다.
해당 성능 지표도 위의 표를 통해 확인할 수 있습니다.
Analysis
Impact of number of layers transferred

다음과 같은 사진을 통해 위에서 언급했던 (Transformer의 구조 -> 12개의 transformer decoder) layer의 개수에 따른 영향도를 보여줍니다.
layer의 개수에 따라 언급했던 NLI와 RACE에 대한 성능 지표를 보여줍니다.
Zero-shot Behaviors
We designed a series of heuristic solutions that use the underlying generative model to perform tasks without supervised finetuning.
We visualize the effectiveness of these heuristic solutions over the course of generative pre-training in Fig 2(right).
요약 : LSTM 모델과의 zero-shot을 비교했을 때, 성능이 뛰어남을 보여줍니다.
(Figure 2. 의 오른쪽)
구체적으로는,
- 성능이 안정적이고 꾸준하다는 것이며 + LSTM은 zero-shot에서 큰 분산을 보임.
라고 언급하고 있습니다.
Ablation studies
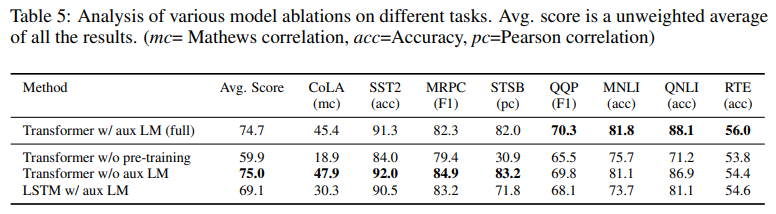
이 섹션에서는 세 가지의 ablation study를 진행합니다.
- auxiliary LM objective를 fine-tuing 단계에서 제외하여 성능을 측정합니다.
: auxiliary objective가 NLI 와 QQP task에서 도움이 됨을 확인할 수 있습니다. 전반적으로 큰 데이터셋일수록 benefit을 받음을 시사한다고 합니다.
- Transformer와 LSTM을 각각 사용해 성능을 비교합니다.
: Transformer가 LSTM에 비해 평균적으로 5.6 만큼 높다고 합니다. MRPC에 대해서만 LSTM이 더 우수하다고 언급했습니다.
- 마지막으로 pre-training의 과정의 유무에 따른 성능을 비교했습니다.
: pre-training의 과정이 없다면(lack of pre-training) full model에 비해 14.8% 만큼 성능이 저하된다고 합니다.
Conclusion
generative pre-training과 discriminative fine-tuning을 통해 강력한 자연어 처리(이해) 모델을 만들기 위한 프레임워크를 도입했습니다. corpus에 대한 pre-training을 통해서 long-range 의존성을 처맇는 능력을 습득하고 다양한 discriminative tasks(위에 언급한 task들)를 성공적으로 해결했습니다.
12개의 데이터셋중에서 9개에서 state-of-the-art에 도달했습니다.
discriminative task에 대해 성능을 높이기 위해 unsupervised (pre-)training을 하는 것은 오랫동안 기계 학습의 목표였는데 실제로 이것이 가능하다는 것을 시사하며 어떤 모델과 데이터 셋에서 잘 작동하는지에 대한 힌트를 제공했습니다.
이 논문에서는 자연어 처리와 다른 영역들에 대해 unsupervised learning의 이해와 방법에 대한 향상에 도움이 되기를 바랍니다.
논문 공부후 드는 생각
GPT 라는 것이 무엇인지 몰랐는데 해당 논문을 읽고 더욱 더 공부할 것이 많아졌다는 생각이 들었습니다.
앞으로 자연어 처리에 대한 기본서를 보면서 기초 개념부터 습득해야 되겠다는 다짐을 했고,
이전까지 발전해 왔었던 다양한 방법론들에 대한 논문을 봐야겠다고 계획을 세우는 동기부여도 된 것 같습니다.
논문에서 잘 이해하지 못했던 개념들(auxiliary objectives, zero-shot, transformer의 구조와 개념 등등..)에 대해 추가적으로 공부를 할 예정이며 어느 정도 공부를 한 후 GPT-2, GPT-3의 논문도 공부를 할 예정입니다.




댓글