이번에 읽고 공부하게 된 논문은
"유튜브 악성 댓글 탐지를 위한 LSTM 기반 기계학습 시스템 설계 및 구현"
"Design and Implementation of a LSTM-based YouTube Malicious Comment Detection System" 입니다.
논문은 KCI를 통해 원문을 내려받을 수 있습니다. (KCI링크 바로가기)
본 논문은 상명대학교의 김정민 연구원과 국중진 교수님이 스마트미디어저널에 등재하여 발간된 논문입니다.
논문은 유튜브라는 매체에서의 악성 댓글을 탐지하는 시스템을 설계, 구현, 성능 평가하는 내용을 담고 있습니다. LSTM 기반의 자연어 처리를 통해 악성 댓글을 판별하고 최종적으로 악성 댓글에 대한 통계를 시각화하는 방법까지 제안합니다.
Abstract

논문의 내용을 요약한 부분입니다.
악성 댓글로 인한 문제가 발생하고 있음을 지적하며 그중 그 폐해가 심각한 유튜브라는 매체에 대해 악성 댓글을 판별하고 탐지하는 시스템을 설계 및 구현했다는 내용을 담고 있습니다.
결론적으로 악성 댓글 검출 부문에서 약 92%의 정확도를 나타냈고, 이를 활용해 악성 댓글의 통계를 자동으로 생성되도록 구현했다고 합니다.
Introduction

논문의 서론 부분입니다.
악성 댓글에 대한 내용과 현황을 통계 자료를 통해 자세히 다루고 있습니다.
-> 경찰청 통계 자료에 의하면 사이버 명예훼손 및 모욕 범죄 발생 건수는 2014년 8,880건에서 2020년 19,388건으로 꾸준히 증가되는 추세이다.
-> 국내에서 유튜브의 조회수는 2020년 12월 기준 88.19%(2,564억 회) 증가하였으며, 누적조회수는 5,472억 회에 이른다.
-> 본 논문에서는 유튜브 콘텐츠의 댓글을 수집하여 데이터셋을 구축하였으며, 악성 댓글을 자동 탐지하여 피해를 줄이기 위한 목적으로 LSTM 네트워크 기반의 기계학습 모델을 이용한 악성 댓글 탐지 시스템의 설계와 구현을 통해 악성 댓글 탐지 성능을 평가하였다.
연구 배경

연구 배경이라 적혀 있는 부분입니다.
제 생각에는 서론의 부분을 더 자세히 다룬 내용인 것 같습니다.
유튜브의 1인당 한 달 시청시간의 통계, 악성 댓글의 정의, 기존 악성 댓글 탐지 시스템의 성능 등에 대한 내용을 서술하고 있습니다.
-> 유튜브는 1인당 한 달에 30시간 34분, 하루에 59분 이상 이용한다. 유튜브 앱 사용자 4천41만 명 중 10대가 13.4%, 20대가 17.2%, 30대가 19.4%, 40대가 21.3%, 50대 이상이 28.7%로 조사됐다.
-> 악성 댓글은 내용에 따라 상대에 대한 비방, 협박 및 저주, 게시판 도배 및 광고, 기타 등으로 나눌 수 있고, 피해 대상에 따라 게시글에 나타난 대상, 게시글 작성자, 댓글 작성자, 기타 등으로 나눌 수 있다. 또한, 악성 댓글의 비율은 약 59%로 높은 비중을 보이고 있다.
-> SVM 기반의 악성 댓글 탐지시스템은 약 87.8%의 정확도를 보인 바가 있으며, ~


마지막으로, 해당 논문에서 구현하는 크롤링 기반의 댓글 수집 내용과 구현 시스템의 구조를 표와 그림을 통해 설명하고 있습니다.
본론
논문의 본론 부분입니다. 논문에서 제안하는 내용이 자세하게 서술되어있습니다.
댓글 크롤링
데이터 수집 방법에 대한 내용이 담겨 있습니다.
다양한 어휘들을 수집하고 학습시키기 위해서 여러 가지 카테고리로 세분화하여 콘텐츠를 선정하고 댓글을 추출했으며, 분포에 대한 경우도 고려했다고 합니다.
댓글 추출은 Youtube Data API v3를 이용해 진행했으며, pandas 라이브러리를 사용해 엑셀 파일로 저장했음을 밝혔습니다.
데이터 정제
(1) 댓글 라벨링
수집한 데이터에 대한 라벨링 및 정제 과정에 대한 내용이 서술되어 있습니다.
일반 댓글로 악성 댓글로 라벨링 했으며, 그 기준에 대한 내용이 기재되어 있습니다.
(2) 결측값 제거
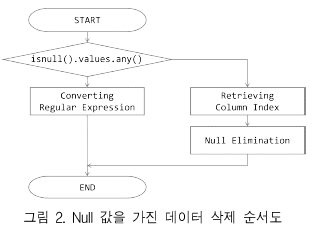
결측값을 분류하여 제거하고 비율을 조정했다는 내용입니다.
그림 2를 통해 과정의 순서도를 제시합니다.
(3) 정규 표현식 변환
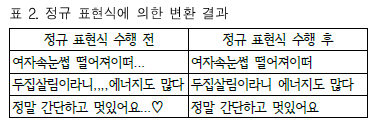
표 2와 같이 정규 표현식을 지정하고 변환을 진행했다는 내용입니다.
정규 표현식의 기준과 방법에 대해 자세한 내용이 기재되어 있습니다.
(4) 토큰화
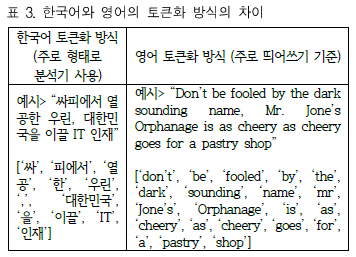
한국어 형태소 분석기인 KoNLPy의 Okt를 사용해 불용어 제거 과정을 거쳐, 토큰화를 진행했다는 내용입니다. 불용어의 지정 기준, 토큰화 과정에 대한 내용이 서술되어 있습니다.
표 3을 통해 해당 내용을 간단하게 확인할 수 있었습니다.
블로그에 한국어 형태소 분석기인 KoNLPy에 대한 간단한 설명 및 구현 글이 있으니 참고하시면 도움이 될 것 같습니다.
NLP 기초 - KoNLPy를 활용한 한국어 형태소 토크나이징(Komoran, Kkma, Okt)
토크나이징(tokenizing) 일반적으로, 자연어 처리를 하기 위해서는 문장을 일정 의미를 지닌 작은 단어들로 나누어야 합니다. 가장 기본이 되는 단어를 토큰(token)이라 합니다. 말뭉치(혹은 문장)가
seokii.tistory.com
(5) 정수 인코딩
토큰화 완료 후 정수 인코딩을 진행했다는 내용입니다.
train 데이터에 대해 정수 인코딩을 진행했으며, 이는 학습하기 위해 텍스트 데이터를 숫자로 인식하려 처리할 수 있기 위함이라 주장합니다. 등장 빈도수가 높은 순서대로 차등 부여했으며, 등장 횟수가 2회 이하라면 해당 과정에서 제외시켰다고 합니다.
(6) 패딩
패딩을 통해 데이터 샘플들의 길이를 일정하게 조절했다는 내용입니다.
약 97% 이상의 댓글에서 길이가 50 이하임을 확인했으며, 학습 모델이 처리 가능하도록 길이를 50으로 지정했다고 합니다.
LSTM 기반의 댓글 감성 분류
RNN, LSTM에 대한 간단한 설명과 그 특징에 대해서 설명합니다.
실험에 대한 세부 수치에 대한 내용이 기재되어 있습니다.
-> 임베딩 벡터의 차원을 100으로 정하고,~
-> 과적합 징후가 4번 발생 시 조기 종료되도록 한다.
-> 검증 데이터의 정확도(val_acc)가 이전보다 좋아질 경우에만 모델이 저장되도록~
-> 에포크 15번 수행으로~
최종적으로, 10번의 에포크 실행해서 멈추었으며 약 92%의 정확도를 보였다고 주장합니다.
PyQt 기반의 데이터 시각화
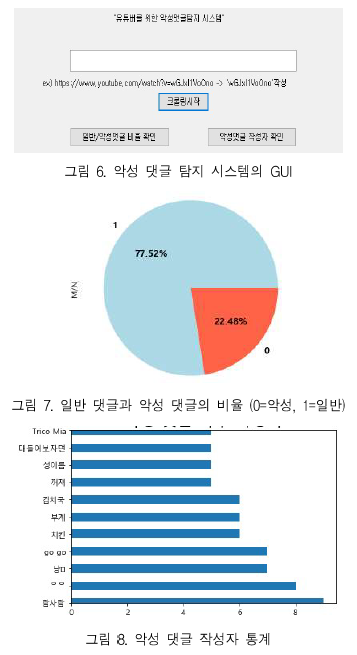
PyQt를 이용해 GUI를 구현했다는 내용이 담겨 있는 부분입니다.
구현한 GUI의 작동 구조에 대한 자세한 내용이 서술되어 있습니다.
-> '크롤링 시작' 버튼을 누르면~
-> '악성 댓글 / 일반 댓글 비율 확인' 버튼을 누르면~
-> '악성 댓글자 확인' 버튼을 누르면~
실험 결과
훈련된 데이의 결과를 통해 정확도를 측정하고, 이 정확도에 근거해 해당 유튜브의 주소를 넣어 댓글을 크롤링하고 그에 맞는 결과가 잘 도출되었음을 확인할 수 있었다고 주장합니다.
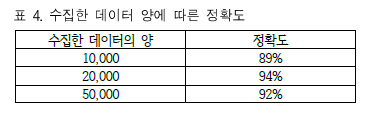
표 4를 통해 학습 데이터의 개수가 늘어날수록 정확도가 향상되지 않았는데,
특정 댓글들이 다양하게 변형된 언어를 감지하지 못하고 일반 댓글 분류되는 상황이 발생하기 때문이라고 밝힙니다. 해당 부분은 맞춤법 교정과 더욱 다양한 언어를 학습시켜 정확도를 높이는 것이 중요하며 보완해야 할 점이라고 주장합니다.
Conclusion

논문의 마지막 결론 부분입니다.
최근 악플에 대한 심각성에 대해 다시 한번 강조하며,
본 연구에 대한 내용 정리와 향후 연구 방향에 대한 내용을 정리하고 마무리합니다.
-> 댓글 데이터 학습을 위해 LSTM 모델을 기반으로~
-> 또한, 본 연구에서 사용된 학습 모델과 소스 코드를 공개함으로써 유튜버를 비롯한 SNS 사용자들이 악성 댓글로 인한 피해 사례를 수집하는데 활용하도록~
공부하며 느낀 점
최근 유튜브 혹은 타 플랫폼에서의 악성 댓글로 인해 인터넷 방송을 진행하는 사람들의 피해가 급증하고 있다는 뉴스를 빈번하게 접할 수 있습니다. 악성 댓글로 인해 인터넷 방송을 진행하는 직업을 가진 사람들이 우울증에 걸리고 극단적으로 이로 인해 자살하는 사례까지 발생하고 있습니다. 개인적으로 악성 댓글의 증가는 급격하게 성장하고 있는 인터넷 관련 산업에서 매우 심각한 문제 중 하나라고 생각합니다.
인공지능 기술과 접목해 해당 문제를 해결할 수 있다면, 그것은 아주 큰 성과가 될 것이며 우리가 살아가는 데 있어 반드시 해결해야 되는 사회 문제 해결 과제라고 생각합니다.
그러한 관점으로 봤을 때, 위 논문을 공부하며 딥러닝 기술에 기반하여 사회 문제를 해결하려고 하는 점에서 인상 깊었습니다. 향후, 통계 자료를 수집해 좋은 인공지능 모델을 만든다면 정말로 해결할 수 있지 않을까라는 생각이 들었습니다.




댓글