논문을 보면서 기계 학습에 대한 공부를 하고자 글 게시를 시작하게 되었습니다.
이번에 공부할 논문은
"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" 입니다.
논문의 저자는 Mingxing Tan , Quoc V. Le 이며,
Image Classification에서의 성능이 좋은 Network Model을 제안한 논문입니다.
논문을 읽으며 핵심 내용을 순서대로 정리하도록 하겠습니다.
Introduction
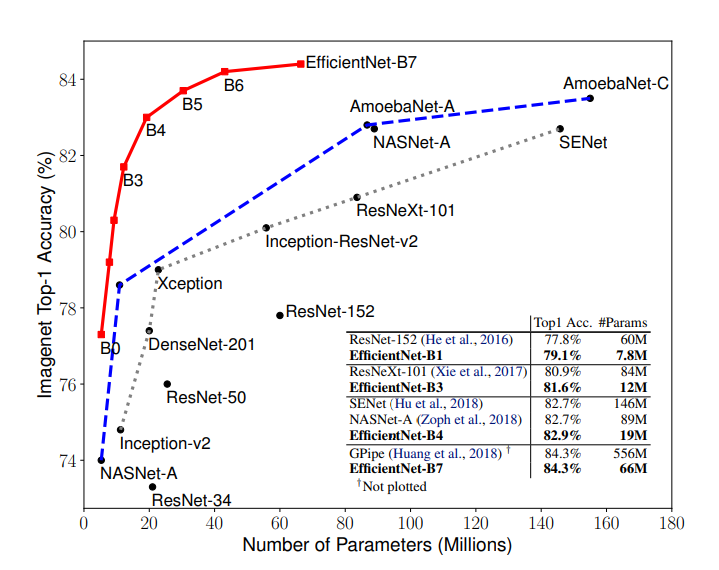
논문은 Intro에서 위와 같은 결과를 보여주고 시작합니다. 저자가 제안한 EfficientNet 모델이 지금껏 다른 ConvNets 모델과 훨씬 뛰어난 성능을 나타냄을 보여주고 있습니다. 저자는 높은 정확도와 함께 해당 모델이 다른 모델들보다 효율적임을 강조합니다. Intro의 내용을 좀 더 자세히 살펴보도록 하겠습니다.
ConvNets의 Scaling up은 정확성을 높이기 위해 널리 사용됩니다.
- ResNet은 더 많은 계층을 layer를 사용하여 ResNet-18에서 ResNet-200으로 확장할 수 있습니다.
- G-Pipe는 baseline모델을 4배 더 크게 확장하여 ImageNet top-1 accuracy인 84.3%를 달성했습니다.
ConvNets의 가장 흔한 Scale up 방법은 depth, width, image resolution의 조정입니다.
- 이전까지는 depth, width, image resolution 중 하나만 조정하는 것이 일반적입니다.
- 수동적으로 조정하는 것은 매우 까다롭고 정확도와 효율성 측면에서 최적의 상태가 아닐 수 있습니다.
논문에서는 ConvNets의 scaling up 과정에 대해서 다시 생각(Rethink)하고자 합니다.
- 정확성과 효율성을 높일 수 있는 ConvNets의 scale-up 방법이 있을까?
경험적 연구에 따르면 네트워크의 width, depth, resolution을 모든 차원에서의 균형을 맞추는 것이 매우 중요하며, 이 균형은 각 요소들을 일정한 비율로 확장해야 합니다.
이러한 관찰을 바탕으로, 단순하면서도 효과적인 Compound Scaling을 제안합니다.
Compound Scaling

(a)는 baseline 모델을 나타내며 (b), (c), (d)는 width, depth, resolution을 조정한 모델 구조입니다.
마지막으로 (e)는 논문에서 제안하는 compound scaling 모델 입니다.
width, depth, resolution을 적절한 비율로 조정하며 최적의 모델을 구현하며, 이를 검증합니다.
Related Work
ConvNet Accuracy
ConvNet은 점점 더 큰 규모로 발전하면서 정확성이 높아졌습니다.
- 2014 ImageNet -> GoogleNet achieves 74.8% top-1 accuracy with about 6.8M parameters,
- 2017 ImageNet -> SENet achieves 82.7% top-1 accuracy with about 145M parameters.
- 2018 ImageNet -> GPipe achieves 84.3% top-1 accuracy with about 557M parameters.
많은 애플리케이션에서 높은 정확도가 중요하지만, 우리는 이미 하드웨어 메모리 한계에 도달했으며 더 높은 정확도를 얻기 위해서는 더 나은 효율성이 필요합니다.
ConvNet Efficiency
Deep ConvNets는 종종 over-parameterized 되어 있습니다.
- Model compression은 효율성과 정확성이 반비례하여 모델 크기를 줄이는 일반적인 방법입니다.
- SqueezeNet, MoblieNet, ShuffleNet과 같이 모바일 크기의 ConvNet의 적용 또한 일반적인 방법입니다.
- 최근에는, MNasNet과 같은 효율적인 모바일 사이즈의 ConvNet을 설계하는 것이 주목받고 있습니다.
그러나 설계 공간이 훨씬 크고 튜닝 비용이 훨씬 비싼 대형 모델에는 이러한 기법들을 어떻게 적용해야 할지 알 수 없습니다.
Model Scaling
다양한 리소스 제약 조건에 따라 ConvNet을 확장할 수 있는 방법은 다음과 같습니다.
- depth를 조정하여 scale-up 혹은 scale-down 시킬 수 있습니다.(예: ResNet -> ResNet-18, ResNet-200)
- WideResNet 과 MoblieNet은 width에 따라 scale 시킬 수 있습니다.
- 입력 이미지가 커지면 FLOPS가 많아져 정확도에 도움이 된다는 것도 잘 알려져 있습니다.
Compound Model Scaling
Problem Formulation
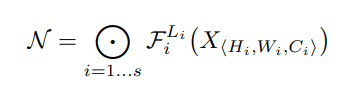
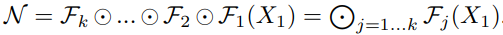
- 최적의 F(i)를 찾는 데 주로 초점을 맞추는 일반적인 ConvNet 설계와 달리, Model scaling은 Baseline Model을 기준으로 정의된 F(i)를 변경하지 않고 네트워크의 길이L(i), 폭C(i), 해상도H(i),W(i) 확장을 시도합니다.
- F(i)를 수정함으로써, Model scaling은 새로운 리소스 제약에 대한 설계 문제를 단순화하지만, 여전히 각 계층에 대해 서로 다른 L(i), C(i), H(i), W(i)를 탐색할 수 있는 큰 설계 공간으로 남아있습니다.

- 설계 공간을 추가로 줄이기 위해 모든 레이어의 배율을 일정하게 제한합니다.
Scaling Dimensions
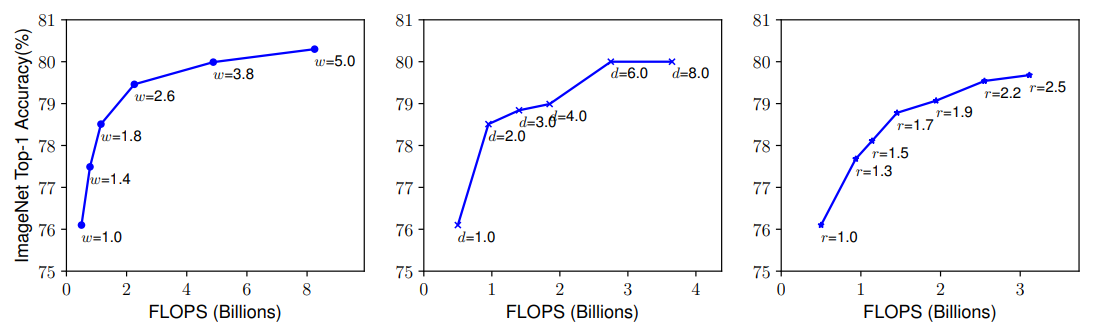
위에서 설명한 어려움 때문에, 기존 방법은 대부분 다음과 같은 차원에서 ConvNet을 확장합니다.
Scaling Dimensions - Depth(d)
- 네트워크의 Depth를 조정하는 것은 많은 ConvNets 모델에서 사용됩니다.
- 직관적으로 더 깊이 있는 ConvNet은 더 풍부하고 복잡한 기능을 포착하고 새로운 작업에 잘 일반화할 수 있습니다. 그러나, vanishing gradient problem으로 인해 더 깊은 네트워크들은 훈련시키기가 어렵습니다. 몇몇 기술로 이러한 문제를 해결해도 매우 깊은 네트워크에서는 정확성 향상은 감소합니다. 대표적으로, ResNet-1000과 ResNet-101을 예로 들 수 있습니다.
- 가운데 이미지는 같은 기준 모델의 depth 계수를 조정한 것에 대한 연구 결과입니다. d의 계수가 매우 높은 결과에서는 정확도가 감소함을 확인할 수 있습니다.
Scaling Dimensions - Width(w)
- 네트워크의 Width를 조정하는 것은 작은 사이즈의 모델에서 흔히 사용됩니다.
- 더 넓은 네트워크들은 fine-grained 특징들을 더 쉽게 훈련시킬 수 있습니다. 그러나, 너무 넓고 얕은 네트워크들은 고수준의 기능들을 포착하기 어렵습니다.
- 왼쪽의 이미지는 같은 기준 모델의 width 계수를 조정한 것에 대한 연구 결과입니다. w의 계수가 높아 질수록 정확도가 빠르게 saturate되는 것을 확인할 수 있습니다.
Scaling Dimensions - Resolution(r)
- 높은 image resolution에서는 fine-grained patterns을 더 잘 포착할 수 있습니다.
- ConvNet은 점점 더 높은 resolution을 사용하는 경향이 있으며 이는 더 높은 정확도로 이어집니다.
- 오른쪽 이미지는 같은 기준 모델의 resolution 계수를 조정한 것에 대한 연구 결과입니다. r의 계수가 높을수록 정확도가 향상됩니다.
위의 분석을 바탕으로 다음과 같은 관찰을 얻을 수 있습니다.
Observation 1
: 네트워크의 width, depth, resolution을 조정하면 정확도를 높일 수 있지만, 모델이 커질수록 증가치가 줄어든다.
Compound Scaling
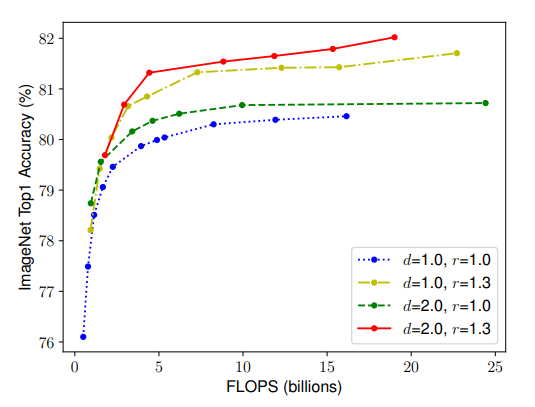
- Scaling 계수가 서로 독립적이지 않다는 것을 관찰했습니다. 직관적으로 고해상도 이미지의 경우 네트워크 깊이를 높여야 더 큰 이미지에 더 많은 픽셀을 포함하는 유사한 기능을 포착할 수 있으며, 따라서 고해상도 이미지에서 더 많은 픽셀로 더 세밀한 패턴을 포착하기 위해서는 해상도가 더 높을 때 네트워크 폭도 늘려야 합니다. 이러한 직관들은 우리가 기존의 1차원 scaling 보다는 서로 다른 계수들을 조정하고 균형을 맞춰야 함을 시사합니다.
- 직관을 검증하기 위해서 위의 그림과 같이 계수들을 조정하여 비교합니다.
- d, r을 변경하지 않고 w만 조정하면 정확도가 빠르게 saturate 됩니다.(파랑)
- 높은 d계수와 r계수와 함께 w를 조정하면 동일한 연산비용 대비 훨씬 더 높은 정확도를 달성합니다.(빨강)
- 이러한 결과를 바탕으로 다음과 같은 관찰을 얻을 수 있습니다.
Observation 2
: 정확성과 효율성을 높이기 위해서는 ConvNet 네트워크의 depth, width, resolution의 균형을 맞추는 것이 중요합니다.
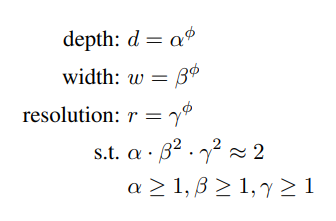
따라서, 다음과 같은 compound scaling method를 제안합니다.
- α, β, γ는 상수이며 grid search를 통해 찾습니다.
- ϕ 는 사용자가 제어할 수 있는 요소이며 가용한 리소스에 따라 적당한 값을 취합니다.
- 제곱이 있는 식의 경우는 FLOPS의 배수 문제 때문입니다.
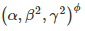
에 의해 최종 FLOPS가 결정됩니다.
EfficientNet Architecture
- Model Scaling은 F(i)를 변경하지 않으므로 좋은 baseline model을 갖추는 것이 중요합니다.
- MNasNet에서 영감을 받아 정확도와 FLOPS를 고려하는 최적화식을 사용합니다.
- 이 논문에서는 latency 대신 FLOPS를 최적화했습니다.
- 위를 바탕으로 기본 모델인 EfficientNet-B0을 만들었다.
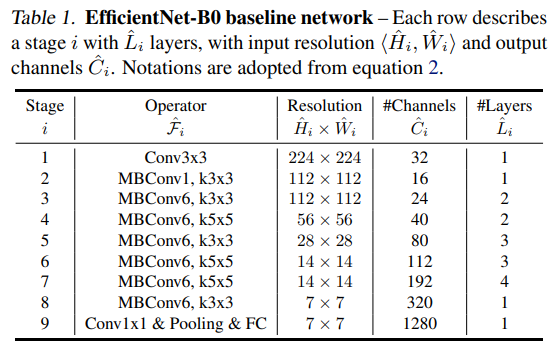
- EfficientNet-B0을 시작으로 두 단계를 거쳐 compound scaling method를 확장합니다.
STEP 1
: ϕ = 1로 고정하고, grid search를 수행하여 α, β, γ의 값을 찾습니다.
이 방법으로 측정된 EfficientNet-B0의 최적값은 α = 1.2 , β = 1.1 , γ = 1.15 입니다.
STEP 2
: α, β, γ 의 값을 고정하고 서로 다른 ϕ 의 값을 사용하여 기준 모델을 확장시킵니다.
결과로 얻은 모델이 EfficientNet-B1~B7 입니다.
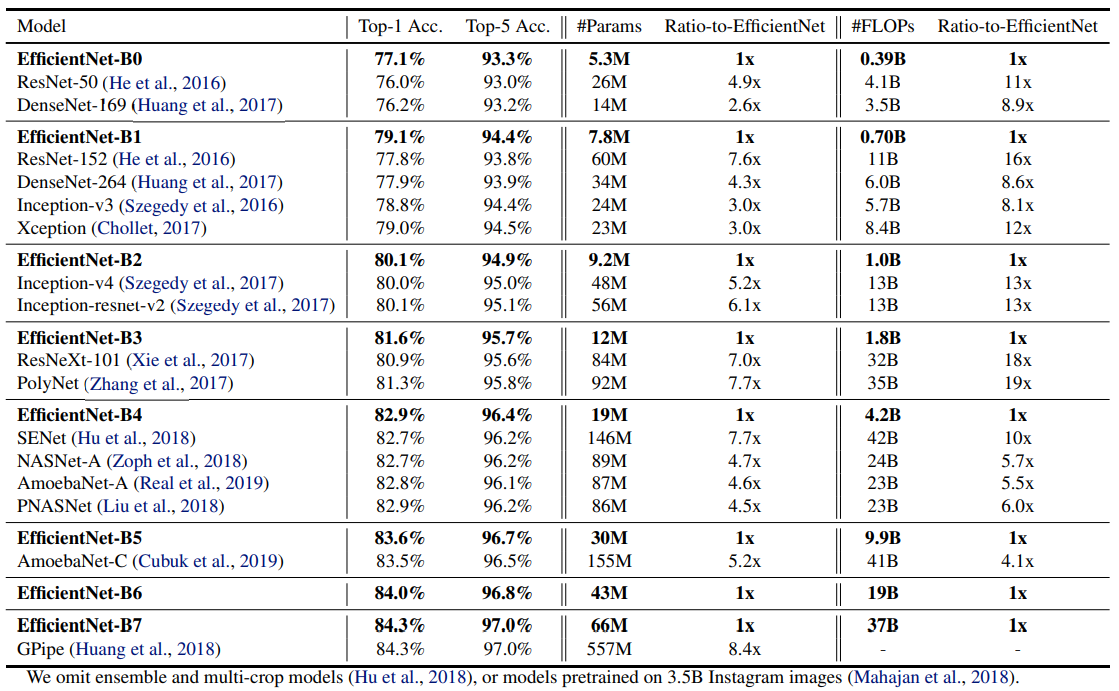
Experiments
- 이 섹션에서는, 존재하는 ConvNet에 우리의 scaling method를 적용하여 평가합니다.
Scaling Up MoblieNets and ResNets
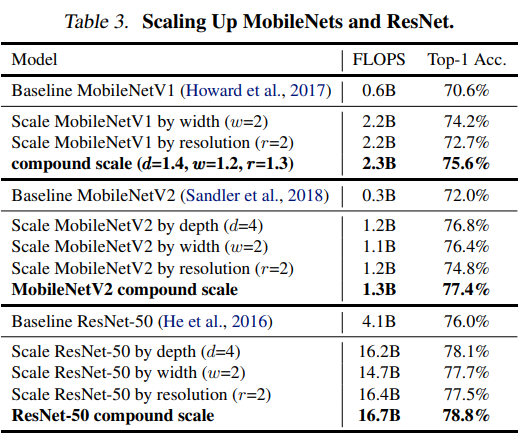
- 기존에 존재하는 MobileNet과 ResNet에 제안한 Scaling method를 ImageNet에 적용한 결과입니다.
ImageNet Results for EfficientNet
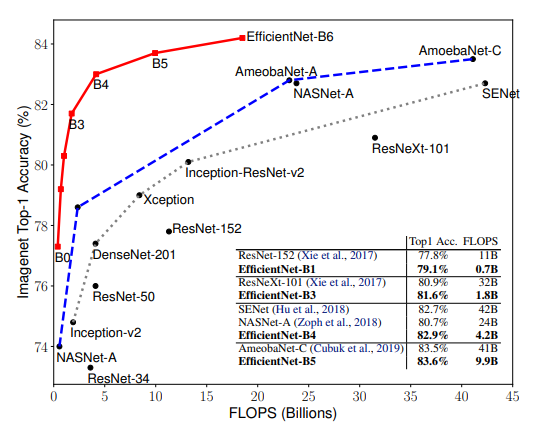
- Intro의 사진과는 다르게 FLOPS를 기준으로 작성한 결과입니다. 거의 유사한 형태를 보이며 EfficientNet을 ImageNet 기반으로 학습한 것입니다.

- latency를 검증하기 위해서 표4와 같이 실제 CPU에서 측정한 결과입니다. 20회 이상 실행하여 평균 값을 측정했습니다.
Transfer Learning Results for EfficientNet
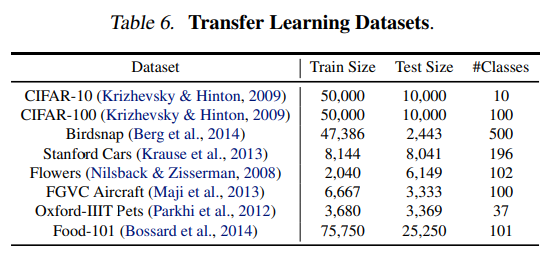
- 일반적으로 사용되는 Transfer Learning 데이터셋 목록에서 EfficientNet을 평가했습니다.
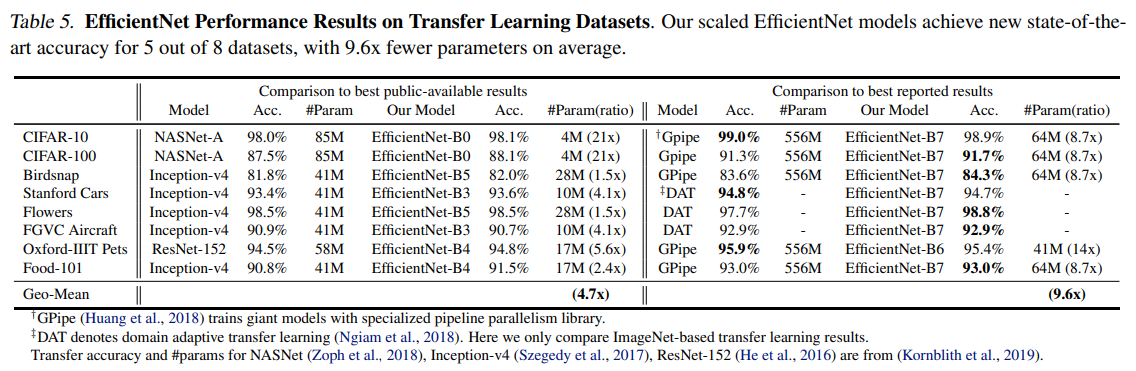
- Table 5 에서는 주요 모델 및 지난 SOTA 모델들과의 성능 비교를 보여줍니다.
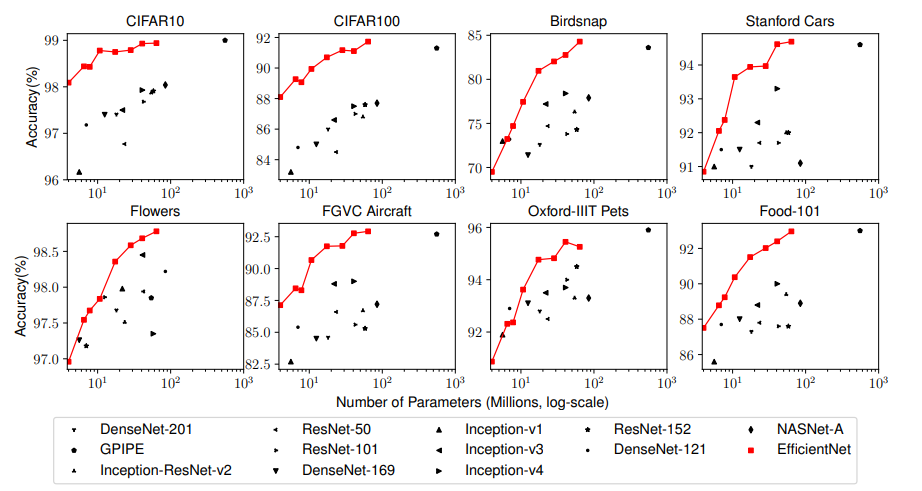
- Figure 6 에서는 기존의 모델들과 비교했을 때, 훨씬 적은 수의 매개변수로 더 나은 정확도를 일관되게 보여줌을 강조하고 있습니다.
Discussion
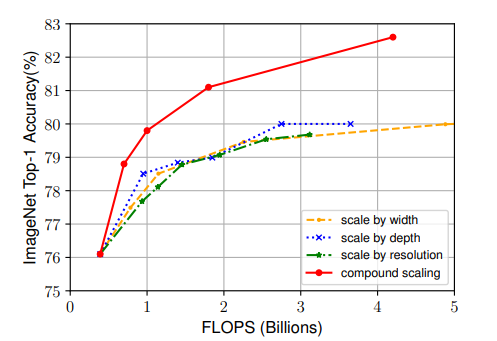
- 제안된 방법이 옳은지 확인하기 위해서, 동일한 EfficientNet-B0 모델을 기준으로 두고 scale의 방법만 바꾸어 ImageNet 성능을 비교했습니다. 논문에서 제안한 compound scaling이 뛰어남을 확인할 수 있습니다.
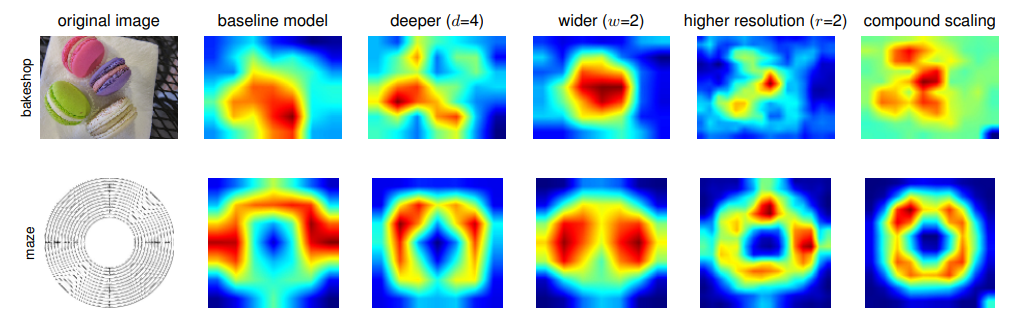
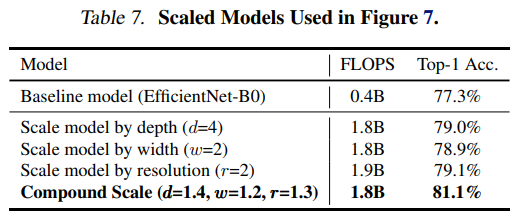
- Compound Scaling이 왜 다른 방법들 보다 나은지 알아보기 위해서 Activation map을 비교하였습니다. 해당 모델들은 모두 동일한 EfficientNet-B0 기준 네트워크에 대해 다른 scale method를 지닙니다. 세부 사항은 위의 Table 7과 같습니다.
- 이미지들은 ImageNet의 검증 세트에서 랜덤으로 선택되어졌으며, compound scaling의 모델이 다른 모델과는 달리 물체와 관련 있는 지역에 초점을 맞추는 경향이 있습니다.
Conclusion
본 논문에서는 ConvNet의 Scaling을 체계적으로 연구하여 네트워크의 width, depth, resolution의 균형을 신중하게 유지하는 것이 중요하지만 누락된 부분임을 식별했습니다. 이 문제를 해결하기 위해서 우리는 모델 효율성을 유지하면서 기본 ConvNet을 보다 원칙적인 방법으로 모든 대상 리소스 제약 조건에 맞게 쉽게 Scaling 할 수 있는 간편하고 매우 효과적인 Compound Scaling method를 제안했습니다. 이 방법을 통해 ImageNet과 일반적인 5개의 Transfer Learning 학습 데이터셋에서 다른 모델들에 비해 모두 성능이 능가함을 입증하였습니다.




댓글