본 논문은 NIPS 2014에서 발표된 논문입니다.
자연어 처리에 관심을 가지고 공부하면서, 꼭 읽어 봐야 할 논문이라고 생각을 하기 때문에
읽으면서 공부하게 되었습니다.
해당 논문에서는 LSTM을 활용해 효율적인 Seq2Seq 기계 번역 아키텍쳐를 제안합니다.
어텐션과 트랜스포머의 개념이 등장할 수 있는 계기가 된 중요한 논문이 아닌가 생각합니다.
해당 논문을 잘 공부하고 이해해야 후에 나오는 개념인 어텐션, 트랜스포머, BERT, GPT 등을 잘 이해할 수 있을것이라 생각했습니다.
요약, 서론, 본문, 결론까지 천천히 살펴보며 공부해보도록 하겠습니다.
논문의 다운로드 링크는 다음과 같습니다.
: https://arxiv.org/abs/1409.3215
Abstract

논문의 요약 부분입니다. 핵심 내용은 다음과 같습니다.
- 이 논문에서 Sequence learning에 대한 일반적인 end-to-end 접근법을 제시한다.
- 우리는 method로 multilayered LSTM를 사용했다.
- 주요 결과는 WMT'14 데이터셋에서 영어를 불어(프랑스어)로 번역 수행한 것에 대해 BLEU 점수 34.8을 달성했다.
- LSTM은 긴 문장에 대해서도 잘 번역을 수행한다.
- 통계적 기계 번역(SMT) 방법의 BLEU 점수는 33.3이 나왔다.
- 통계적 기계 번역에서 나온 1000가지 가설(hypotheses)과 LSTM을 같이 사용해 BLEU 점수를 재측정한 결과 36.5를 달성했다.
- 문장에서 단어의 순서를 뒤집어(reversing) 수행했더니 성능이 훨씬 올라갔음을 증명했다. 이는, 문장을 뒤집었을 때, 최적화 문제가 더 쉬워지기(optimization problem easier) 때문이다.
Introduction
논문의 서론 부분입니다.
서론의 첫 문단입니다.
첫 문단에서는 딥러닝(DNN)이 다양하고 많은 어려운 문제들을 해결할 수 있으며 좋은 성능을 보여준다는 것에 대한 언급을 합니다.
- Deep Neural Networks are extremely powerful manchine learning ~
- ~they can perform arbitrary parallel computation for a modest number of steps.
- ~they learn an intricate computation.
- ~can be trained with supervised backpropagation~
서론의 두 번째 문단입니다.
이 부분에서는 딥러닝(DNN)의 한계에 대해서 서술합니다.
딥러닝의 입력과 출력이 고정된 차원을 가지는 한계점을 지닌다고 합니다.
(DNNs can only be applied to problems whose inputs and targets can be sensibly encoded with vectors of fixed dimensionality.)
그래서 이러한 한계 때문에, 발화 인식이나 기계 번역 같은 sequential한 문제들에 대해 한계를 지닌다고 주장합니다.
- It is a significant limitation, since many ~ with sequences whose lengths are not known a-priori.
- ~speech recognition and machine translation are sequential problems.
서론의 세 번째 문단과 Fig1. 입니다.
여기에서는 이러한 어려운 문제인 sequence to sequence 문제를 어떻게 해결했는지 제시합니다.
논문에서는 LSTM(Long Short-Term Memory)을 사용해 앞서 언급한 문제를 일반적으로 해결할 수 있다고 주장합니다. LSTM을 사용해 입력 데이터에서 큰 크기의 고정된 차원의 벡터를 추출하고, 다른 LSTM을 사용해 입력 데이터에서 추출한 그 벡터를 사용해 출력 시퀀스를 추출하는 구조입니다.
- In this paper, we show ~ Long Short-Term Memory (LSTM) architecture can solve general sequence to sequence problems.
- The idea is to use one LSTM to read the input sequence,~
- ~then to use another LSTM to extract the output sequence from that vector (fig. 1).

네 번째 문단입니다.
이 부분은 논문에서의 접근법이 이전에 있었던 어떠한 논문의 구조와 비슷하다고 언급합니다.

서론의 나머지 부분입니다. 다음 항목의 내용을 언급하고 있습니다.
- 데이터셋의 내용과 BLEU 점수에 대한 내용 / 요약 부분과 같습니다
- 최종적으로, LSTM과 통계적 기법(SMT)를 같이 사용해 BLEU 36.5를 달성했다. 이 수치는 여태까지의 최고 점수와 거의 유사하다.
- LSTM은 매우 긴 문장에 대해서도 잘 처리하는 모습을 보였다.
- LSTM의 유용성(앞서 언급한 내용과 동일)
The model
모델의 구조와 수식에 관한 내용이 설명된 부분입니다.

처음엔 RNN에 대한 수식이 등장합니다. 기존 RNN에 대한 설명을 해줍니다.
\(x_{1}\) 부터 \(x_{T}\)개 까지의 입력값의 단어가 존재하고 \(y_{1}\)부터 \(y_{T}\)까지의 출력 값 결과가 나옵니다.
히든 스테이트 값(\(h_{t}\))은 이전까지의 히든 스테이트 정보와 현재 단어의 정보를 조합해 시그모이드를 취한다고 설명합니다.
그러나, RNN은 입력과 출력의 길이가 다를 때는 사용하기 어렵다고 언급합니다.

그래서 일반적인 방법으로 하나의 RNN을 입력 시퀀스를 고정된 크기의 벡터로 바꾸는 것이고 또 다른 RNN을 사용해 고정된 크기의 벡터를 출력 시퀀스로 바꿔주는 것입니다.
이것이 바로 인코더와 디코더의 구조라고 보시면 될 것 같습니다.
하지만, RNN은 long range temporal dependencies의 문제를 해결하기 힘들기 때문에 LSTM을 사용하면 이를 해결할 수 있다고 주장합니다.

LSTM을 사용했을 때 입력 부분(인코더)과 출력 부분(디코더)의 길이가 다를 수 있다고 설명합니다.
또한, 입력 부분에서 고정된 차원의 벡터 표현(\(v\))을 받고 그 벡터를 사용해 디코더 부분을 통해 각각의 출력을 뽑아냅니다.

앞서 언급한 설명과 구현이 다르다고 언급합니다.
먼저, 인코더 부분의 LSTM과 디코더 부분의 LSTM에 사용되는 파라미터(parameters)가 다르다고 설명합니다.
다음으로 성능을 높이기 위해서 LSTM을 4개의 층을 만들어 사용한다고 말합니다.
마지막으로, 앞서 언급했었던 입력 문자의 순서를 바꾸는 것입니다. 이것 또한, 성능 향상에 도움이 되었기에 사용했다고 언급합니다.
Experiments
실험에 관한 내용입니다.
Dataset details

WMT'14에 대한 데이터셋 내용을 설명합니다.
Decoding and Rescoring

먼저 학습할 때와 테스트할 때의 수식을 설명합니다.
두 식 모두 딥러닝을 학습할 때의 일반적인 수식입니다.

또한 빔 서치(beam saerch)를 활용해 EOS(End of Sequence)값이 나올때까지의 target sentence 중에서 가장 확률값이 높은 경우를 선택한다고 설명합니다.
(빔 서치에 대한 내용은 제가 잘 모르기에 추가적으로 공부를 해야 될 것 같습니다.)
Reversing the Source Sentences

앞서 언급했던 문장의 순서를 바꾸는 것에 대한 내용입니다.
입력 문장의 순서를 바꾸었더니 성능의 향상이 있었으며 이 현상에 대한 완벽한 설명은 어렵지만, 단어의 순서를 바꾸었더니 데이터에 대한 short term dependencies가 발생했고 이것이 도움이 된것이 아닌가 추측한다고 말합니다. 이외에도 부가적인 설명이 기재되어 있습니다.
Training details

학습 시의 세부사항 대한 내용입니다.
learning rate, batch size 등등 세부적인 수치를 어떻게 조정했는지에 대해 말하고 있습니다.
Parallelization

병렬화 작업에 대한 내용입니다.
- ~so we parallelized our model using an 8-GPU machine.
- Our models have 4 layers of LSTMs, each of which resides on a separate GPU.
Experimental Results
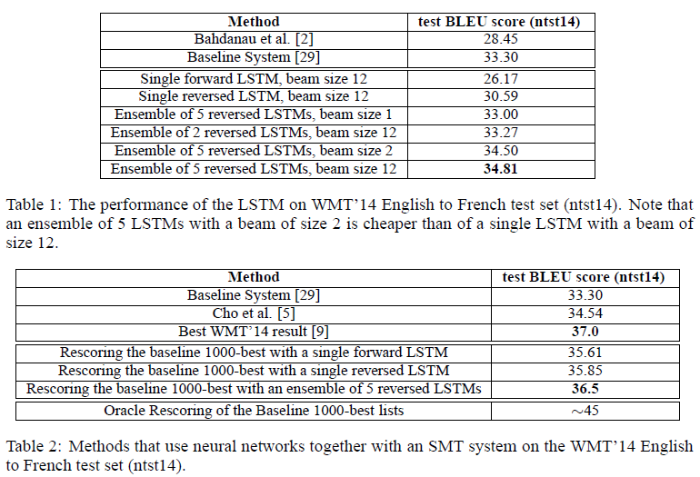
실험 결과에 대한 내용입니다.
표 1에서는 Baseline System과 LSTM, beam, reversed LSTM의 앙상블 등의 조합을 사용해 BLEU 점수를 측정한 결과를 제시합니다.
아래의 표 2에서는 baseline(통계적 시스템)과 LSTM을 같이 사용했을 때 성능이 뛰어나게 측정되었음을 제시합니다.
Performance on long sentences
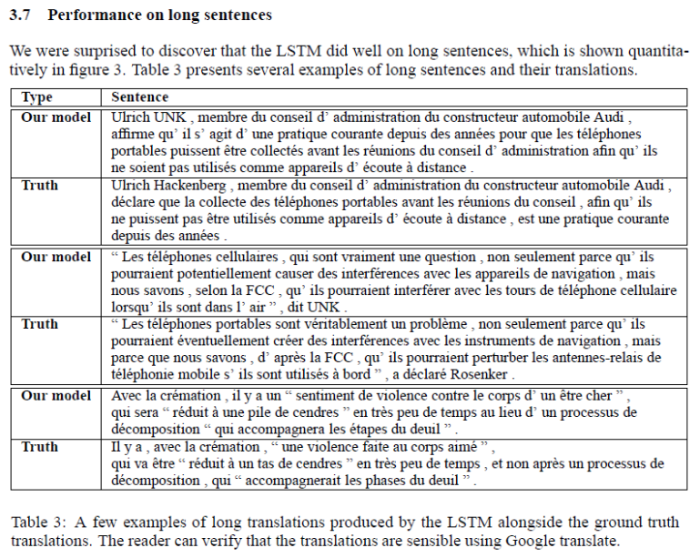
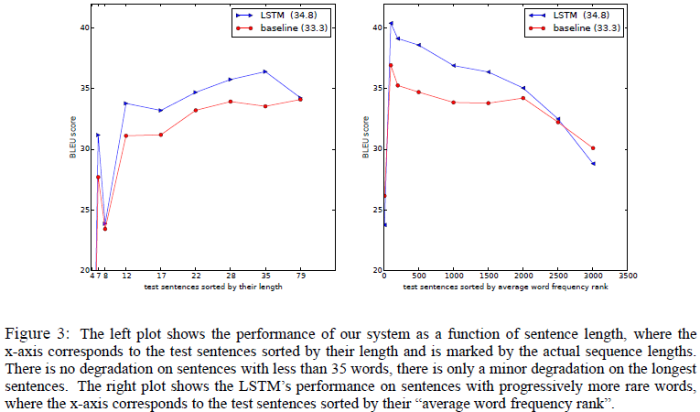
표 3의 예시, Figure 3을 제시하며 긴 문장에 대해서도 성능이 뛰어났음을 주장하는 부분입니다.
Model Analysis
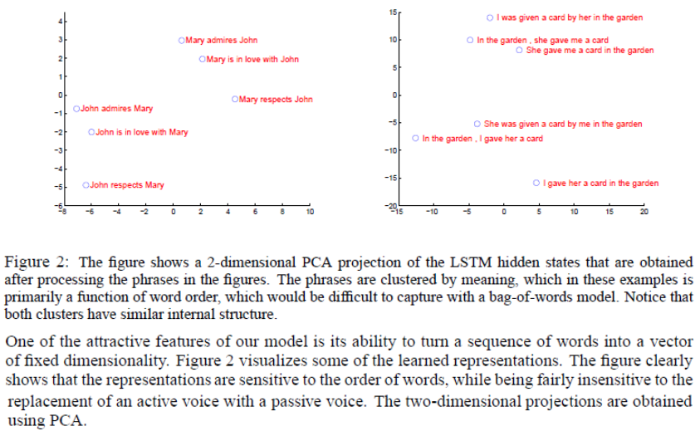
Figure 2를 통해 LSTM의 hidden states를 PCA를 통해 2차원으로 나타낸 것을 보여줍니다.
그림을 통해 비슷한 의미의 문장끼리 잘 clustering된 모습을 볼 수 있습니다.
의미별로 잘 분류가 되었고, 좋은 성능을 보인다는 것을 입증하고 있습니다.
Conclusion

논문의 결론부분입니다.
- LSTM을 깊게 쌓아서 기존의 통계적 기법과 비교했을 때 더 좋은 성능을 달성했음을 입증했다.
- 입력 단어의 순서를 바꿈으로써 더욱 성능을 높일 수 있었다.
- LSTM이 매우 긴 문장에 대해서도 정확하게 번역을 할 수 있었다.
- 이러한 결과들이 다른 sequence to sequence 문제에 대해서도 좋은 결과를 보일 것이라 추측한다.




댓글