이번에 읽고 공부하게 된 논문은
"딥러닝을 이용한 법률 분야 한국어 의미 유사판단에 관한 연구"
"Deep Learning Based Semantic Similarity for Korean Legal Field" 입니다.
논문은 KCI를 통해 원문을 내려받을 수 있습니다. (KCI링크 바로가기)
본 논문은 한국과학기술원의 김성원 연구원님과 인하대학교 박광렬 연구원님이 정보처리학회논문지에 등재하여 발간된 논문입니다.
Abstract

논문의 요약 부분입니다.
본 논문은 기존의 전문적인 용어가 많이 쓰이는 법률 분야의 검색방법을 개선했다는 내용입니다.
법률 도메인의 문장에 자연어 처리 기술을 적용해 문장 간의 유사성을 판단하는 데 최적화된 임베딩 방법을 제시합니다.
Introduction

논문의 서론 부분입니다.
서론에서는 최근 자연어 처리 기술이 발전함에 따라 법률과 같은 도메인과 결합해 많은 연구가 진행되고 있음을 설명합니다. 또한, 본 논문에서 제안하고자 하는 바를 간단히 설명하고 논문의 서술 구조에 대해 기재합니다.
-> 본 논문에서는 그중에서도 법률 분야의 문장들을 검색에 특화되도록 효과적으로 임베딩을 하고, BERT 기반으로 태스크를 전이학습 하는 방안에 대해서 제안하고자 한다.
-> 본 논문에서 제시하고자 하는 것은 다음과 같다. 첫 번째로는 ~ , 두 번째로는 ~
Related Work
논문의 관련 연구에 대한 내용이 서술되어 있는 부분입니다.
법률 분야의 자연어처리 동향
법률 분야에서 자연어처리 기술을 적용했을 때의 이점에 대해서 설명합니다.
또한, 대표적인 법률 인공지능 연구에 대해서 설명하는데,
(1)임베딩 기반 방법론 (2)기호 기반 방법론의 내용이 서술되어 있습니다.
-> 표현 학습(Representation Learning)이라고도 불리는 임베딩 기반 방법론은 법적 사실과 지식을 임베딩 공간에 표현하는 것을 기본으로 한다. 딥러닝 기법을 활용하여 판결 예측, 법률 문답 등의 작업에 효과적이라는 것이 다수의 연구 결과에서 도출된 바 있다.
->기호 기반 방법론은 구조화된 예측 모델이라고도 불리며, 이름에서 알 수 있듯 사건의 타임라인, 당사자들의 관계 등의 구조로부터 핵심 정보나 법적 요소를 추출한다.
해외에서의 적용 사례를 소개합니다. (미국, 중국)
국내의 법률 자연어처리 기술에 관한 연구와 개발을 소개합니다.
(1)법률 빅데이터 생태계 구축 (2)법률 인공지능 서비스 개발의 내용입니다.
국내 법률 관련 데이터의 부족을 지적하며 최근에는 AIHub 등을 통해 빅데이터가 구축되고 있음을 밝혔습니다. 또한, 법제처의 핵심 추진 과제로도 추진되고 있다는 내용이 기재되어 있습니다.
마지막으로 논문에서의 제안을 소개합니다.
-> 본 논문에서는 법률 분야 자연어처리 중 일상 언어로 전문적인 법률 분야의 문장과의 의미 유사도를 파악하고, 데이터를 검색할 방안을 제시하곶 한다. 리걸테크 산업의 발전을 전문 법률 전문가뿐만 아니라, 법을 전문으로 배우지 않은 일반 시민들에게도 진입 장벽을 낮출 수 있도록 하고자 한다.
BERT
자연어처리의 BERT 모델에 대한 설명이 서술되어 있습니다.
자연어처리 분야에 관심이 있다면 BERT에 대한 내용은 반드시 알아야 된다고 개인적으로 생각합니다.
구글링, 논문 리뷰를 통해 해당 내용을 자세하게 공부하시는 것을 추천드립니다.
TF-IDF
TF-IDF 표현에 대한 간단한 내용이 서술되어 있습니다.
블로그에 원-핫 표현, TF 표현, TF-IDF 표현에 대한 내용을 간단하게 정리했습니다.
원-핫 표현, TF 표현, TF-IDF 표현
원-핫 표현 (one-hot representation) 원 핫 표현은 0벡터에서 시작해 주어진 문장에 대해서 등장하는 단어가 있으면 값을 1로 설정하는 것. 다음의 문장들을 예시로 들겠습니다. Time flies like an arrow. Fruit
seokii.tistory.com
Universal Sentence Encoder
-> USE(Universal Sentence Encoder)는 의미론적인 문장 임베딩을 가능하게 하는 모델이다.
-> USE는 Word2Vec, GloVe와 같이 단어 단위의 임베딩이 아니라 문장 단위의 임베딩을 통하여 성능 향상을 입증하였다.
-> USE에서는 Transformer 또는 Deep Averaging Network(DAN) 인코더와 같은 2가지의 인코더를 필요에 따라 사용하는데, 본 논문에서는 더 높은 정확도를 보이는 Transformer의 인코더를 사용하는 모델을 구현하였다.
법률 분야 의미 유사판단 데이터셋
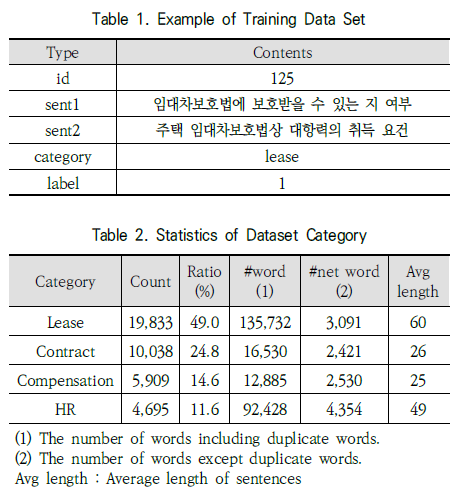
Table 1과 Table 2의 자료와 함께 연구에서의 데이터셋 구축 방법에 대해 설명합니다.
1차적인 과정을 진행하는 일반적인 법률 지식을 가지고 있는 작업자와 2차적인 과정을 진행하는 전문적인 법률적 지식을 가지고 있는 작업자를 구분하고, 공공기관에서 제공하는 법률 상담 사례를 수집해 여러 카테고리로 분류해 데이터를 구축했음을 설명합니다.
그 외에도 데이터셋의 총 개수와 학습, 시험 데이터의 비율, 라벨링 정보 등의 자세한 데이터셋에 대한 설명이 기재되어 있습니다.
임베딩 및 실험방법
TF-IDF를 이용한 키워드 기반 임베딩
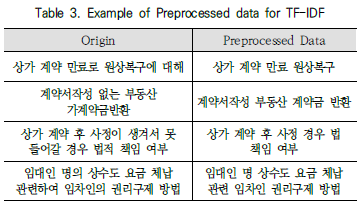
TF-IDF를 이용해 키워드 기반 임베딩을 진행하였고, Table 3의 형태와 같이 한국어 형태소 분석기인 MeCab을 활용해 문장 중 명사만 남기는 방식으로 전처리했다고 설명합니다.
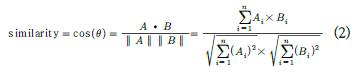
또한, 위의 식인 코사인 유사도를 통해 전체 데이터셋 내의 문장에 대한 임베딩 벡터값과 입력 문장의 임베딩 벡터값을 비교해 유사도를 측정했다고 합니다. 유사도는 0~1 사이의 값이며, 높은 순으로 10개의 값을 출력합니다.
USE를 이용한 의미 기반 임베딩
Universal Sentence Encoder(USE)를 통해 단어가 아닌 문장 자체를 의미 기반으로해 임베딩 하는 모델을 사용했다고 설명합니다. 키워드가 중심이 아닌 문장 자체를 임베딩함으로써 문장간 맥락이나 의미의 유사성을 벡터간 차이로 도출할 수 있게 했음을 밝혔습니다.
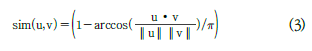
코사인 유사도를 사용하는 것은 위와 같으나, 각 거리(angular distance)로 변환하기 위해 across을 취했다고 주장합니다.
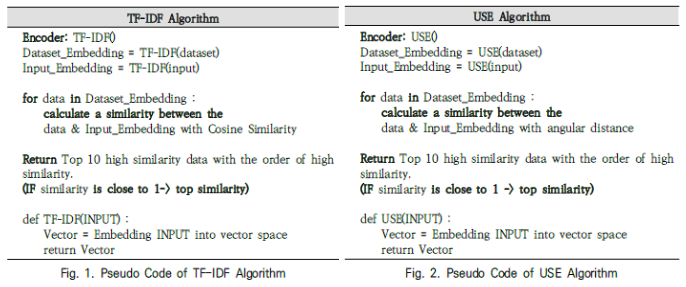
위의 Fig 1과 Fig 2는 각각 TF-IDF 기반 임베딩 알고리즘과 USB 기반 임베딩 알고리즘에 대한 내용입니다.
실험방법

위의 TF-IDF 기반과 USB 기반의 임베딩 방법으로 유사도가 높은 후보 문장들을 필터링하고 위의 Fig 3인 BERT 모델에 전달해 맥락까지 유사한 문장을 필터링합니다.
이 BERT 모델은 전이학습 모델이며, BERT-base Multilingual Cased 모델(기반 모델)로 한국어 Wikipedia를 포함한 다국어 언어처리가 되는 사전학습 모델에 위의 임베딩 방법들을 조합하여 검색을 했다고 합니다.
-> 하지만 본 논문에서는 BERT모델 자체의 성능이 아니라 키워드 기반 임베딩 또는 의미 기반 임베딩과 조합하여 사용하였을 때 법률 분야의 검색 성능향상에 미치는 영향을 객관적으로 파악하기 위하여 기반 모델을 기준으로 전이학습을 진행하여 성능을 평가하였다.
실험에서 수행하고자하는 태스크는 2개의 입력 문장이 주어졌을 때 그 문장의 의미가 동일 또는 유사한가(1), 아니면 유사하지 않은가(0)의 이진 분류를 판단하는 것이며 그 이후에 자세한 실험 방법이 기재되어 있습니다.
실험 결과
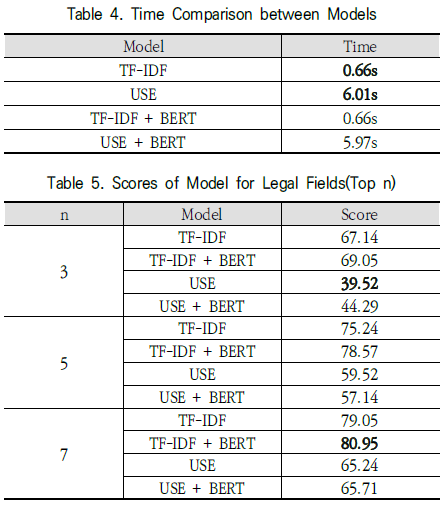
Table 4와 Table 5를 통해 실험의 결과를 설명합니다.
해당 논문에서는 기존 성능평가의 방법으로는 법률 분야에서 의미의 유사성을 판단하는 성능을 측정할 수 없기 때문에 자체적으로 성능 평가의 지표를 수립하였다고 주장합니다.
-> 성능을 나타내는 socre는 모델이 제시하는 similarity가 높은 문장 Top-n개 중에서 유사 문장으로 라벨링(1)이 된 문장의 여부를 평가하였다. 1로 라벨링이 된 문장을 포함하고 있는 경우 Hit로 판단하여, 전체 실험갯수 중 Hit의 비율을 산정한다.
Table 5를 통해 TF-IDF모델과 BERT모델을 결합한 모델이 가장 좋은 성능을 보여줌을 알 수 있고, USE모델은 오히려 BERT모델과 결합했을 때 성능이 하락하는 경우가 있음을 알 수 있습니다.
Table 4를 통해 실행시간이 가장 짧은 모델은 TF-IDF 단독모델 사용이고, 가장 긴 모델은 USE 단독모델 사용임을 알 수 있습니다.
실험 분석
TF-IDF vs USE
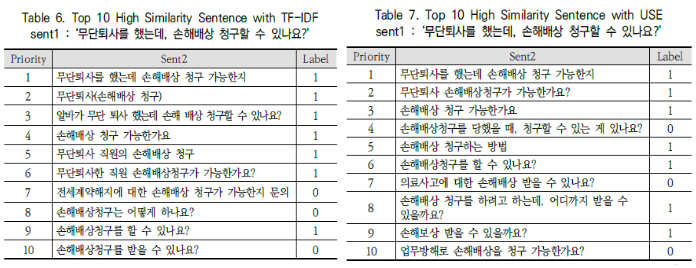
Table 6, Table 7의 예제를 통해 TF-IDF 방식과 USE 방식을 비교 분석합니다.
해당 부분에서는 TF-IDF 방식이 성능이 더 좋으며, 작성한 Table과 함께 자세히 설명합니다.
TF-IDF vs TF-IDF + BERT
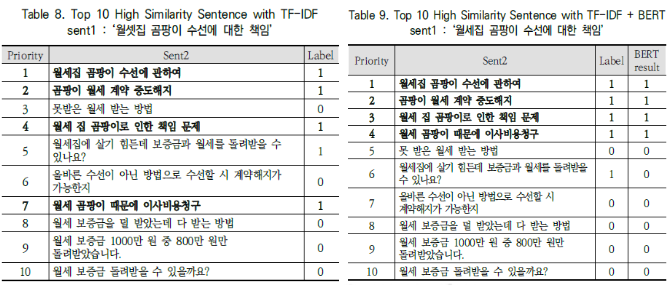
마찬가지로 Table 8, Table 9의 예제를 통해 TF-IDF 방식과 TF-IDF + BERT 방식을 비교합니다.
-> 실제 검색결과라고 가정했을 시 BERT 모델을 결합한 모델이 실제로 더 양질의 검색결과를 제공하는 것을 알 수 있다.
USE vs USE + BERT
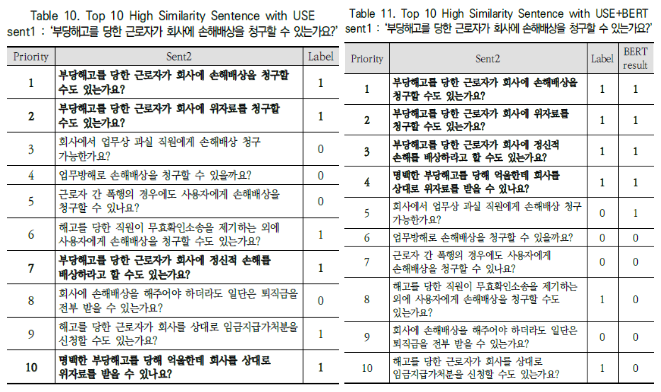
USE 방식을 사용했을 때 발생할 수 있는 단점을 설명합니다.
또한, Table 10과 Table 11을 통해 두 방식을 비교합니다.
Conclusion

해당 논문의 결론 부분입니다.
공부하며 느낀 점
리걸테크라는 분야를 잘 몰랐었는데, 이번 논문을 공부하면서 리걸 테크 분야에 대해서 알게되었고, 이 리걸테크라는 분야에 자연어 처리 기술을 적용해 연구를 했다는 것이 인상깊었습니다.
법률에 대한 전문 지식이 없는 일반인에게는 법률 분야에 대한 검색이 어려울 수 밖에 없다고 생각하는데, 여러 임베딩 방법과 자연어 처리 모델을 통해 일반 사용자들도 쉽게 검색을 하는 방법을 제안한 그러한 발상이 정말 놀라웠습니다.
자연어 처리 분야는 공부할수록 매력적인 분야인것 같다고 생각했고 앞으로도 더 열심히 해당 분야에 대한 공부를 꾸준하게 해야겠다는 다짐을 할 수 있었던 논문이었습니다.




댓글