본 논문은 ICLR 2015에서 발표된 논문입니다.
Seq2Seq에서 Encoder-Decoder의 구조가 처음 등장하게 되고,
이 구조에서 Encoder부분에서 Fixed-Length Vector를 추출하고 이 벡터를 사용해 다시 Decoder부분의 작업을 수행하는데, 본 논문에서는 Fixed-Length Vector의 한계점에 대해 언급하고 극복하려는 접근법을 제시합니다.
기계 번역 분야에서 처음으로 어텐션의 개념이 도입된 논문이면서 Seq2Seq와 마찬가지로 NLP분야를 공부함에 있어 반드시 읽어봐야하는 논문이라고 생각합니다.
논문 저자의 이름을 따 바다나우 어텐션이라고도 잘 알려져 있습니다.
논문의 저자를 보면 조경현 교수님이 저술한 논문으로도 잘 알려져 있습니다.
논문 링크 : https://arxiv.org/abs/1409.0473
꼼꼼히 읽으며 논문을 정리해보겠습니다.
해당 논문을 읽기 전에 Seq2Seq 논문을 꼭 읽어보는 것을 추천드립니다.
https://seokii.tistory.com/137
[ML 논문 공부 - 009] Sequence to Sequence Learning with Nueral Networks (NIPS 2014)
본 논문은 NIPS 2014에서 발표된 논문입니다. 자연어 처리에 관심을 가지고 공부하면서, 꼭 읽어 봐야 할 논문이라고 생각을 하기 때문에 읽으면서 공부하게 되었습니다. 해당 논문에서는 LSTM을 활
seokii.tistory.com
Abstract

논문의 요약 부분입니다.
- Neural Machine Translation은 최근 기계 번역 분야에 제안된 접근법이다.
- 본 논문에서 우리는 인코더-디코더 구조에서 고정된 크기의 벡터를 사용하는 것이 병목(bottle neck)이라 추측하고, 이를 Soft-Search를 사용해 source sentence에서 연관된 부분을 찾아 target word를 예측하는 것을 제안한다.
Introduction

서론의 1~3번째 문단입니다.
Neural machine translation(신경망 기계 번역)이 최근 제안된 개념이면서 어떠한 것인지를 설명하고 있습니다. NMT는 통계적 번역 시스템(phrase-based translation)과는 다르게 따로따로 분리되어 튜닝된 매우 많은 sub-components로 구성되어 있고 큰 하나의 신경망이 훈련되어 문장을 읽고 올바르게 번역합니다.
그리고 Seq2Seq에서 등장한 인코더-디코더의 개념을 설명하면서, 고정된 길이의 벡터를 사용한다는 것을 언급합니다. 이렇게 fixed-length vector를 사용하는 것은 필요한 정보를 고정된 길이로 압축한다는 특성상 긴 문장에 대해서 성능이 급속하게 떨어질 수 있다고 시사합니다.

서론의 4번째부터 마지막까지의 문단입니다.
앞서서 언급한 문제를 해결하기 위해서 확장된 인코더-디코더의 모델을 제안한다 말합니다.
이 모델은 인코딩 과정에서 기존의 고정된 길이의 벡터 하나를 생성하는 것이 아니라,
일련의 벡터들을 생성한다고 말합니다. ( input seneteces into a sequence of vectors )
따라서, 입력 문장에 대해서 하나의 고정된 길이의 벡터로 만들 필요가 없고, 이에 긴 문장에 대해서도 더 잘 대처할 수 있게 설계되었다고 주장합니다.
마지막으로, 다시 한 번 기존의 인코더-디코더 구조의 성능보다 뛰어나며 길이에 상관없이 성능 향상이 이뤄짐을 언급하며 서론을 마칩니다.
Background: Neural Machine Translation

신경망 기계 번역에 대한 전반적인 배경에 대해서 서술하는 부분입니다.
첫 문단에서는 확률론적인 관점에서 NMT에 대한 정의를 하며 설명합니다.
그 다음 문단부터 Seq2Seq에 대한 언급을 하며 RNN을 사용해 인코더-디코더 구조의 신경망 기계 번역에 대해 설명합니다. 또한, Seq2Seq에서 같은 구조 및 고정된 길이의 벡터와 LSTM을 사용해 기존의 통계적 기계 번역 시스템과 거의 유사한 성능을 달성했음을 서술합니다. 또한, 이후에 다른 개념들을 도입하면서 통계적 기반의 시스템의 성능을 뛰어넘었음을 설명합니다.
RNN Encoder-Decoder

인코더-디코더 구조에 대한 설명을 수식과 함께 설명한 부분입니다.
Seq2Seq 논문과 같은 내용이기에 이해하기 어렵지 않을 것이라 생각합니다.
Learning to Align and Translate

Section 3에서는 신경망 기계 번역의 새로운 아키텍쳐를 제안하는 부분입니다.
새로운 아키텍쳐는 양방향 RNN을 인코더로 사용하며, 디코더 부분은 디코딩하는 과정에서 입력 문장에 대해 검색을 수행하는 과정을 진행합니다.
디코더 부분은 Section 3.1을 통해, 인코더는 Section 3.2를 통해 설명한다고 밝히고 있습니다.
또한, Figure 1을 통해 제안 모델의 구조를 보여줍니다.
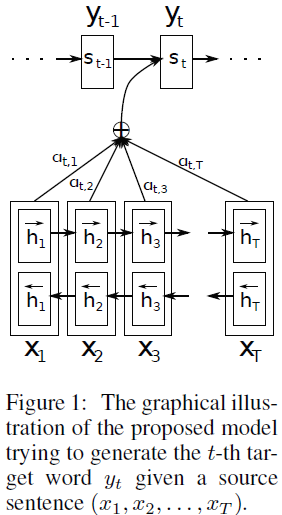
Encoder: Bidirectional RNN for Annotating sequences
논문에서 순서는 Decoder -> Encoder의 순서로 기재되어 있지만, 쉬운 이해를 위해서 Encoder -> Decoder순으로 읽었습니다.

입력 문장은 Encoder 구조를 거치게 됩니다. 논문에서는 bidirectional RNN을 사용해 양방향에 대한 정보를 모두 활용하는 방법을 제안합니다. BiRNN은 forward RNN과 backward RNN으로 구성되어 있는데,
Forwad RNN은 순차적으로 입력 받아 hidden state(\(\overrightarrow{h_{1}} , ... ,\overrightarrow{h_{Tx}}\))를 생성하며,
Backward RNN은 역방향으로 입력 받아 hidden state(\(\overleftarrow{h_{1}} , ... ,\overleftarrow{h_{Tx}}\))를 생성합니다.
따라서, 입력 \(x_{j}\)에 대해서 \(\overrightarrow{h_{j}}\), \(\overleftarrow{h_{j}}\)를 연결해 hidden state인 \(h_{j}\)를 생성합니다.
이렇게 함으로써, RNN의 특성 덕에 가까운 위치에 있는 정보들을 더 많이 포함시킬 수 있습니다.
Decoder: General Description

디코더 부분에서의 조건부 확률을 구하는 식은 앞선 RNN Decoder 부분의 수식과 거의 유사하지만, 차이점은 \(c_{i}\) 로써, target word(\(y_{i}\))에 따라 각자 구분된 context vector를 사용한다는 점입니다.
이러한 각각의 context vector를 구하기 위해서 앞서 언급된 인코더 부분에서 구했던 hidden state( \(h_{i}\) ) 값에 포함된 annotations의 가중치 합(weighted sum)을 계산합니다. 계산식은 아래와 같습니다.

순서대로 context vector, 가중치, 가중치의 \(e_{ij}\)를 구하는 식입니다.

context vector를 구하는 과정에서 마지막 식의 \(a()\) 는 alignment model로서, 하나의 feed forward neural network로 전체 학습 시스템과 함께 학습되어 soft alignment를 계산한다고 설명합니다.
논문에서는 context vector \(c_{i}\)를 expected annotation이라고 정의합니다.
이러한 expected annotation인 \(c_{i}, e_{ij}, \alpha_{ij}\) 등은 인코더의 hidden state인 \(h_{j}\)의 중요도를 반영하고 디코더 부분의 hidden state인 \(s_{i}\)를 결정합니다.
즉, source word와 어느 정도 연관성이 있는지를 측정하고 weight 값을 기반으로 반영한다고 볼 수 있습니다.
제안하는 새로운 접근 방식으로 정보를 분산시키고 선택적으로 검색할 수 있다는 의미입니다.
이를 통해 기존 인코더에서 모든 문장을 하나의 고정된 길이의 벡터로 변환하는 작업보다 보다 효율적임을 주장합니다.
Experiment Settings
Dataset

실험 환경에 대한 내용이며, 해당 부분에서는 데이터셋에 대한 설명이 기재되어 있습니다.
WMT'14 데이터셋을 사용해 영어를 불어로 번역하는 task를 수행했음을 설명합니다.
그 외의 세부 구성에 대한 내용이 있습니다.
Models

실험 환경에서의 학습 모델에 관한 내용입니다.
논문에서는 두 가지 형태의 모델을 훈련했는데, 기존의 다른 논문에서 제안한 RNN Encoder-Decoder 모델과 논문에서 제안하는 RNNsearch 모델입니다.
각 모델의 구조(RNN, BiRNN, numbers of hidden units .. )와 학습 방법 등에 대한 내용을 설명합니다.
Results
Quantitative Results
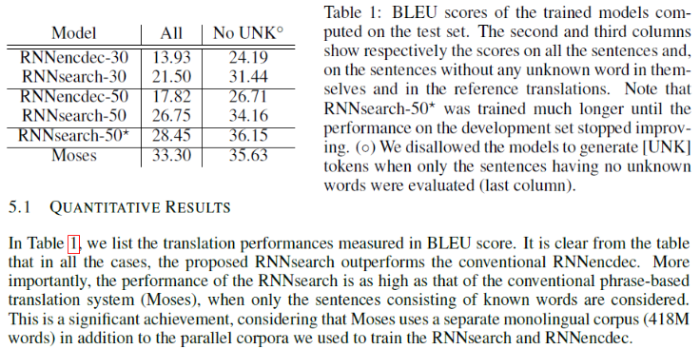
Table 1을 제시하며 정량적 결과에 대한 내용을 설명합니다.
Table 1은 기존의 RNNencdec와 제안하는 RNNsearch 모델에 대해 길이를 기준으로 분류하고 BLEU 성능 평가를 진행한 결과입니다. 표를 통해 제안하는 모델이 기존 인코더 디코더 방식의 모델보다 성능이 더욱 뛰어남을 확인할 수 있으며, 특히 제안한 모델에 대해 unknown word를 제외한 데이터만을 사용해 성능 평가를 진행한 결과 기존 통계 기반 모델의 SOTA 모델의 성능을 뛰어넘었다는 것이 큰 성과라고 할 수 있습니다.
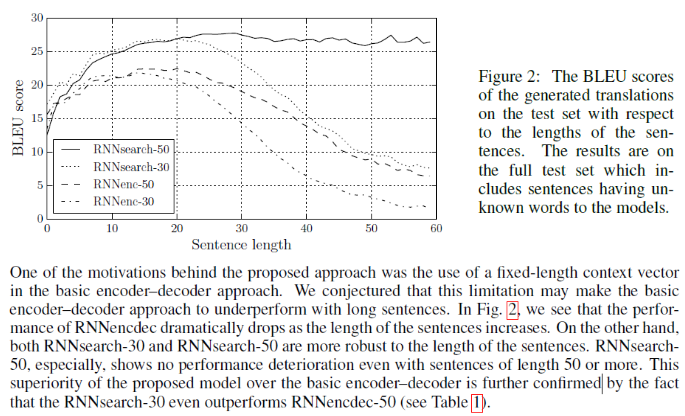
또한, 논문에서는 fixed-length context vector를 사용하는 것이 긴 문장에 대해 성능을 떨어뜨리는 원인이라고 추측했는데 제안하는 구조에서 이를 해결함으로써 긴 문장에 대해서도 성능을 유지할 수 있었다고 주장합니다. Figure 2를 제시하며 주장에 대한 근거를 뒷받침합니다. 특히, 50 길이가 넘어가면 성능이 매우 뛰어남을 주장하고 있습니다.
Qualitative Analysis
Qualitative Analysis - Alignment

논문에서는 제안된 모델이 생성된 번역 단어와 입력 문장 사이의 align을 잘 검사할 수 있으며, Figure 3을 통해 근거를 제시합니다.
Figure 3는 Eq 6의 annotation weights인 \(\alpha_{ij}\)를 시각화한 자료입니다.
이 자료를 통해 target word를 생성할 때 source sentence의 어느 부분을 더 중요하게 생각했는지 확인할 수 있습니다.
예를 들어 (a) 에서는 영어와 불어간 형용사 명사의 순서가 다름에도 불구하고 잘 번역된 모습을 확인할 수 있고, (d)를 통해 soft-alignment와 hard-alignment의 차이점을 언급하며 강점이 있음을 설명합니다.
Qualitative Analysis - Long Sentences

이 부분에서는 다양한 예제를 통해 정성 분석을 진행하고, RNNsearch와 RNNencdec를 비교합니다.
RNNdec는 30개의 단어를 생성한 이후 실제 의미를 벗어나기 시작했고 제안 모델은 그렇지 않다는 내용입니다. 이러한 정성 분석은 제안하는 아키텍쳐가 긴 문장에 대해 더 잘 번역한다는 것을 확인시켜주는 근거라고 주장합니다.
Related Work
Learning to Align

관련 연구인 Handwriting synthesis에 관한 내용입니다.
해당 내용과 논문에서의 제안법을 비교합니다.
Neural Networks for Machine Translation

NMT의 등장부터 시작해 NMT의 전반적인 내용을 설명합니다.
제안하는 모델이 가장 뛰어남을 주장합니다.
Conclusion

논문의 결론 부분입니다.
인코더-디코더라고 불리는 전통인 NMT의 접근법에서 고정된 길이의 벡터를 추출하고 그 벡터로 디코더에서 계산을 수행하는 한계를 우리의 제안을 통해 극복했다라는 내용입니다.
위에서 설명한 내용들을 짧게 요약한 부분입니다.




댓글