이번에 공부할 논문은 "Enhanced Sequential Representation Augmented with Utterance-level Attention for Response Selection" 입니다.
본 논문은 고려대학교의 임희석 교수님과 자연어처리 연구실의 황태선, 이동엽, 이찬희 연구원님들이 저술한 논문입니다.
NLP의 Response Selection task에 있어 utterance-level attention을 제안한 논문입니다.
논문 링크 : http://workshop.colips.org/dstc7/papers/15.pdf
About DSTC7
논문에서 언급된 DSTC7에 관한 내용입니다.
http://workshop.colips.org/dstc7/workshop.html
DSTC7
Workshop Registration --> Workshop Program 08:00-09:00Registration Opening 09:00-09:10Welcome Remarks from DSTC Organizing Committee (Paper) (Slides)Koichiro Yoshino 09:10-09:25DSTC7 Task 1: Noetic End-to-End Response Selection - Track 1 Overview Ch
workshop.colips.org
Abstract

논문의 요약 부분입니다.
Response selection은 여러 개의 후보군들 중에서 올바른 반응에 대해 선택하는 task입니다.
논문에서는 DSTC7에 대한 end-to-end reponse selection model을 제안합니다.
Dialog system에서 발화 수준(utterance-level)의 표현을 고려하는 것이 중요한데, 제안하는 모델은 utternace-level attention과 함께 word-level ESIM을 사용하는 것입니다.
utternace-level attention을 활용하면 많은 응답 후보군들 중에서 가장 관련 있는 답을 찾을 수 있습니다.
Introduction
논문의 서론 부분입니다.
reponse selection에 대한 간단한 정의와 구체적인 예를 Table 1을 통해 설명합니다.
- Response selection은 대화 시스템이 올바른 반응을 선택할 수 있도록 하는 중요한 task로 여겨집니다.
(Reponse selection is considered to be a crucial task for building conversational agests that ~)
논문에서는 word-level representation을 구성하기 위해 ESIM 모델을 사용하는데,
ESIM(Enhanced Sequential Inference Model)은 NLI task에서 뛰어난 성능을 보였습니다.
이 ESIM을 통해 문맥에서 의미 있는 단어와 정보를 포착합니다
또한 utterance-level embedding을 사용하는데,
utternece-level embedding은 word embeddings + sentence embeddings + positional embeddings로 이루어집니다.
최종적으로, word-level ESIM + utterance-level embeddings + attention mechanism 의 조합으로 적절한 reponse를 선택하게 됩니다.
Background
3.1 Related Work
관련 연구에 대한 설명이 기재되어 있는 섹션입니다.
reponse selection task에서는 보통 LSTM을 기반으로한 dual encoder 모델을 사용합니다.
본 논문에서 제안하는 ESIM 방식은 어텐션 메커니즘을 사용하며 훨씬 뛰어난 성능을 보였습니다.
그러나 위의 방법들은 word-level LSTM을 사용하기 때문에 입력 값이 길어질수록 문맥 정보가 손실될 수 있는데 이를 해결하기 위해 utterance-level sequence representations을 사용할 수 있습니다.
이를 사용한 다른 연구에서는 문장과 관련된 단어를 포착할 수 없어 대화 문맥과 후보군 사이의 관계를 잘 찾을수 없었습니다. 이에 본 논문에서는 word-level, utterance-level을 둘 다 사용하여 이를 해결하는 것을 제안한다고 주장합니다.
3.2 Task Description

DSTC7에서 수행하는 task와 데이터셋에 대한 자세한 내용을 다루고 있습니다.
- DSTC7의 Sentence selection track은 대화 시스템에서 여러개의 후보들 중 다음에 올 적절한 대답을 찾는 task입니다.
- 해당 task에서는 두 가지 데이터셋이 주어집니다. 모두 두 사람간의 multi-turn 대화 데이터입니다.
Our Approach

논문에서 제안하는 바를 Figure 1으로 구조를 제시하고 자세한 설명을 여러 섹션을 통해 진행합니다.
- NLI task 에서 우수한 성능을 보이는 ESIM model을 확장시킨다.
- utteurance embeddings을 사용
- attention mecanism을 적용
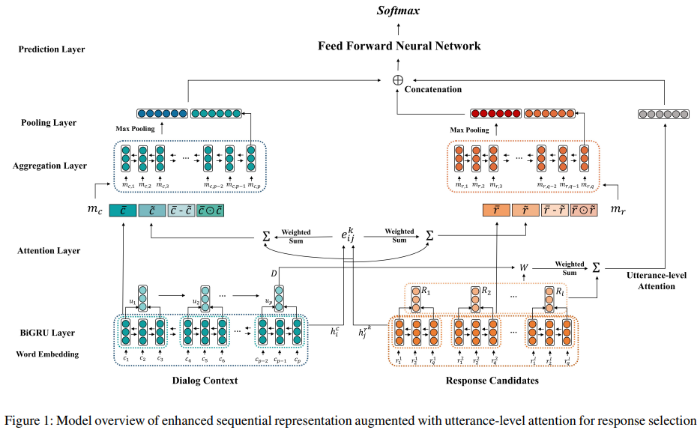
4.1 Dual Encoder

Dual Encoder 부분에 대한 내용입니다. Figure 1에서 가장 아래쪽에 해당하는 부분입니다.
대화 문맥과 대답 후보들을 표현하기 위해서 dual encoder을 두 개의 GRU를 사용해 만듭니다.
이러한 두 개의 GRU(BiGRU)를 통해 양방향의 hidden state를 만들고,
양방향의 hidden state를 합쳐 Sequence representations을 만듭니다.
4.2 Attention Layer

Attention Layer에 대한 자세한 설명입니다.
hidden states로 dialog context, response candidates의 어텐션 점수를 계산합니다.
그리고 각각 어텐션 메커니즘을 적용해 연관된 단어를 찾게 됩니다.
수식으로 재정의하고 구한 값을 튜플로 얻게 되고, 행렬 곱과 같은 계산과 concatenate를 진행합니다.
4.3 Aggregation Layer

BiGRU를 사용해 matching information을 aggregate합니다.
이를 통해 dialog context와 responses사이의 관계를 포착하는데 도움이 될 수 있습니다.
4.4 Polling Layer

Aggregate Layer에서 결과값이 산출되면, Pooling Lyaer를 통해 Max Pooling을 진행합니다.
수식은 위의 논문 내용과 같습니다.
4.5 Utterance-level Attention Layer
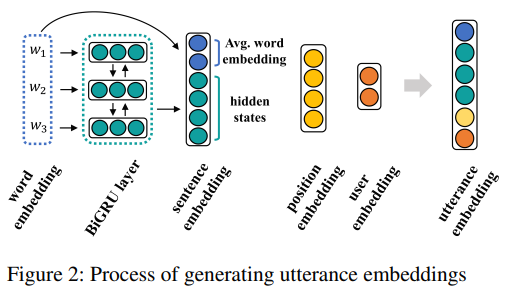

Figure 2와 함께 Utterance-level Attention layer에 대한 설명이 제시된 부분입니다.
word level의 dialog representation을 사용했을 때 발화의 길이가 길어지거나 대화의 turn이 길어진다면 정보의 손실이 발생할 수 있는데, 논문에서 제시하는 utterance-level representation을 통해 정보의 손실을 막을 수 있다는 내용이며, Figure 2와 같은 몇 가지의 feature을 통해 생성한다고 설명합니다.
(Sentence Embedding + Position Embedding + User Embedding)
4.6 Sentence Embedding

Utterance-level Layer의 Sentence Embedding에 관한 내용입니다.
Sentence Embedding = average of the word embeddings + BiGRU representations
4.7 Position Embedding

Utterance-level Layer의 Position Embedding에 관한 내용입니다.
Positional information은 다음 말을 선택하기 위한 중요한 요소이며, 해당 논문에서는 position embedding을 sentence embedding과 연결했다고 설명합니다.
4.8 User Embedding

Utterance-level Layer의 User Embedding에 관한 내용입니다.
사용자 정보를 입력하기 위해서 user embedding을 사용했다는 내용입니다.
예를 들면 논문에서의 Advising 데이터셋에서는,
advisor의 역할은 학생들을 도와 적절한 강의를 찾게 해주는 것이고
student의 역할은 정확한 정보를 advisor로 부터 얻는 것입니다.
이러한 역할에 대한 내용을 원-핫 인코딩을 통해 정보를 담았다고 설명합니다.
4.9 Prediction Layer

최종 예측을 하는 Prediction Layer에 대한 설명입니다.
Experiments
본 논문에서의 실험 환경 및 실험 결과에 대한 섹션입니다.
5.1 Datasets

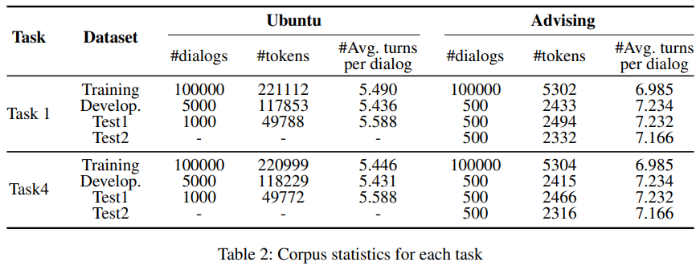
실험에 쓰인 두 가지 데이터셋에 대한 세부 사항입니다.
5.2 Evaluation Metric

성능을 측정하기 위한 평가 지표에 대한 내용입니다.
두 가지 지표를 사용했음을 알 수 있습니다.
5.3 Negative Sampling

실험을 하는 데 있어 Negative Sampling을 사용합니다.
100개의 응답 후보의 수를 효율성을 위해 20개로 줄였다는 내용입니다.
10개에서 30개 까지 5개의 단위로 실험을 했는데 20개에서 가장 좋은 성능을 보였다고 주장합니다.
5.4 Training Details

학습 세부사항에 대한 내용입니다.
pre-trained, dropout, optimizer, learning rate 등에 대한 내용이 자세하게 기재되어 있습니다.
5.5 Results
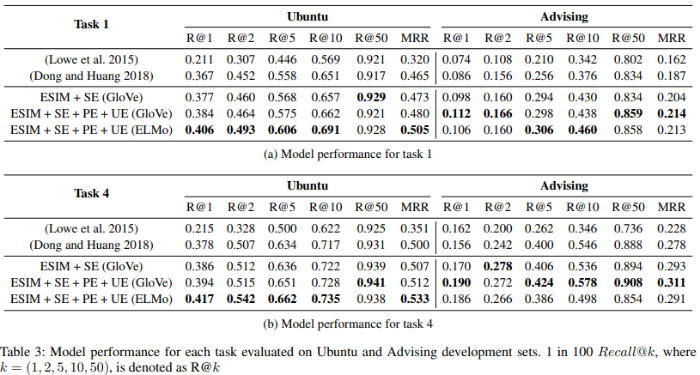

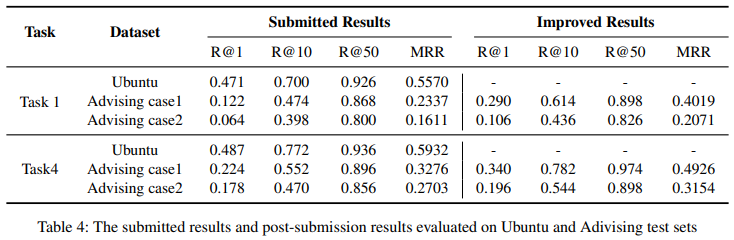

Table 3, 4를 제시하며 그에 대한 결과를 설명하는 부분입니다.
Conclusion

논문의 결론 부분입니다.
multi-turn 방식의 대화 시스템에서 word-level과 utterance-level의 정보를 모두 활용해서 reponse selection task에 대한 end-to-end 모델을 제안한 논문입니다.
utterance-level의 정보를 사용해 뛰어난 성능을 입증한 것이 굉장히 유의미한 결과라고 할 수 있습니다.
공부하며 느낀 점
response selection task에 있어 기존의 word-level의 표현만 사용해서 task를 수행했는데,
이 논문에서는 utterance-level의 표현을 사용해 어텐션 메커니즘을 적용하고 task를 수행한 것이 인상깊었습니다. NLP 분야를 공부하면 할수록 그 세부 분야가 엄청 많고, 공부할 내용이 많다는 것을 새삼 느꼈습니다.
NLP 분야를 공부하기로 결정했는데, 이렇게 세부 분야가 엄청 많아서 더 깊이 연구하고 싶은 분야를 정해야 하는지 전반적으로 모두 공부해야하는지 고민됩니다..
논문을 읽다 보면 모든 세부 분야가 흥미롭고 재미있게 느껴져서 다행인것 같습니다.
이번 논문을 통해 response selection이라는 세부 분야에 대해서 배울 수 있었고,
이렇게 체계적으로 layer을 구성하고 모델을 설계하는 것이 정말 대단하다고 느꼈졌습니다.
공부를 더 열심히 해야겠다고 다짐하게 되는 논문이었습니다.




댓글