이번에 공부할 논문은
"Character-Level Feature Extraction with Densely Connected Networks" 입니다.
본 논문은 고려대학교의 임희석 교수님과 자연어처리 연구실의 이찬희, 이동엽 연구원님과 Amazon Alexa의 김용범 연구원님이 저술하신 논문입니다.
논문에서는 Densely Connected Networks를 사용해 Feature Extraction을 수행하는 방법을 제안합니다.
실험에서는 Slot tagging, POS tagging, NER의 총 세가지 task를 수행하고 성능을 측정했습니다.
논문을 꼼꼼히 읽어보며 공부해보도록 하겠습니다.
논문 링크 : https://arxiv.org/abs/1806.09089
Abstract

논문의 요약 부분입니다.
chracter-level feature은 NLP task를 수행함에 있어 중요한 과정이며 이러한 feature을 추출할 때 인간의 노동을 줄이기 위해 CNN 또는 RNN과 같은 신경망이 쓰입니다.
논문에서는 CNN은 위치독립적인 특성을 지니며, RNN은 순차적 처리 특성때문에 느리다고 주장합니다.
이를 해결하기 위해 논문에서는 densely connected network를 사용해 자동으로 character-level feature을 추출하는 방법을 제안합니다.
제안하는 방법은 특정 task나 언어에 제한하지 않고 CNN, RNN 기반 방법보다 빠르며 효율적임을 주장합니다.
Introduction
논문의 서론 부분입니다.
NER, POS tagging, Slot tagging과 같은 NLP task에서 feature extraction을 효율적으로 진행하는 것은 매우 중요한데, CNN 또는 RNN과 같은 신경망 구조를 통한 방법은 사람의 노동력이 필요하지 않고, 우수한 성능을 보이기 때문에 최근 많은 관심을 끌고 있습니다.
그러나 앞서 언급한 바와 같이 CNN은 문자의 순서를 구분하는 것이 어렵고, RNN은 순차적 특성 때문에 처리 속도가 느립니다.
논문에서는 densely connected network를 사용해 보다 효율적이고 효과적인 feature extraction 방법을 제안합니다. 3가지의 핵심 benefit을 설명합니다.
1) 제안된 방법은 hand-carfted feature이나 데이터 전처리과정이 필요하지 않습니다.
2) 제안된 방법은 효율적으로 character-level feature을 추출하며 동시에 효과적이다.
3) 특정 task 혹은 언어에 의존하지 않는 방법이다.
논문에서 연구를 통한 contributions는 다음과 같이 정리합니다.
1) 우리는 효과적이면서도 효율적인 character-level feature extraction 기법을 제안합니다.
2) 실험과 평가를 통해 제안하는 방법이 CNN 혹은 RNN보다 우수함을 입증합니다.
3) 3가지(slot tagging, POS tagging, NER) NLP task에 대해 SOTA를 달성하거나 혹은 거의 근접하게 달성했습니다.
Related Work
feature extraction과 그와 관련된 tsak인 POS tagging, NER과 관련된 연구에 대한 내용이 상세하게 정리되어 있는 섹션입니다. 신경망 구조가 feature generation에 적용되기 이전부터 최근 연구까지의 과정을 많은 논문을 인용하며 시간 순서대로 나열하고 있습니다.
- Prior to the introduction of neural architectures for character-level feature generation, ~
- In recent years, metohds that utilize neural networks ot automatically extract character-level features have been proposed. The most widely adopted and successful method for this is CNN.
- Another effectve way of generating feature vectors from a variable length sequence of characters is to use RNN.
Proposed Method
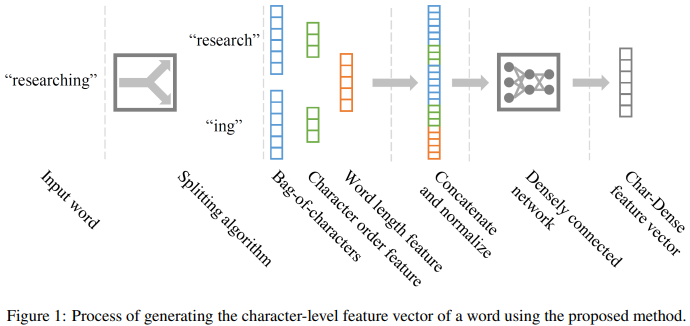

논문에서 제안하는 기법은 BOC(Bag-of-Characters)표현 기반인데, 이는 쉽게 애너그램이 되기 쉬우며 단어충돌 문제가 발생합니다. (i.e. 동일한 벡터 표현을 갖는 다른 단어)
따라서, 위에서 언급한 bnefit을 유지하면서 단어 충돌을 최소화시키는 것이 주 목적입니다.
이를 위해 BOC를 사용해 단어를 분리하고 character order, word length의 feature에 대한 벡터를 추출하고 세 가지를 concatnate 및 normalize를 수행합니다.
정규화를 진행하는 식은 위의 식(1)과 같으며 최종적으로 나온 벡터 값을 densely connected network의 입력값으로 넣고 final dense character feature vector를 결과값으로 받습니다.
4.1 Splitting Words

앞서 언급한 단어 분리에 대한 자세한 설명입니다.
단어 충돌을 줄이기 위해서 분리 알고리즘을 통해 단어를 분리합니다.
n-gram 기반으로 말뭉치에서 가장 많은 빈도를 차지하는 단어를 우선순위로 지정한 k개 만큼까지 나누게 됩니다. k 값은 하이퍼파라미터 값으로 조정할 수 있다고 설명합니다.
Algorithm 1을 통해 자세한 알고리즘 식을 설명합니다.
4.2 Character Order Feature

character order feature 벡터를 추출하는 과정에 대한 내용입니다.
모든 문자는 수치화된 값으로 표현할 수 있으며 따라서 비교가 가능하다고 설명합니다.
논문에서 정의한 식 (2), (3)을 통해 이전의 k로 나눈 값들의 비교를 수행하고 특징 벡터들을 추출합니다.
4.3 Word Length Feature

Word Length Feature 벡터를 추출하는 과정에 대한 설명입니다.
원-핫 인코딩을 통해 0~20의 값으로 지정하며, 20이 넘어가는 경우도 20으로 지정했다고 설명합니다.
Model
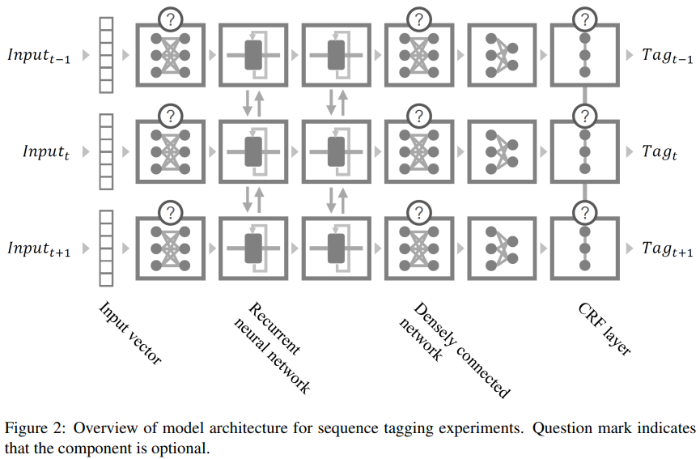
해당 섹션은 sequence tagging 모델 아키텍쳐에 대한 자세한 설명이 기재된 부분입니다. Figure 2를 통해 모델 아키텍쳐를 제시합니다.
5.1 Sequence Tagging with Bidirectional RNN

Sequence Tagging을 진행하기 위해 양방향 RNN의 구조를 사용했다고 설명합니다.
논문에서는 long-term dependency에 더 강한 LSTM을 RNN 대신 사용했으며, 양방향 구조에서 특징 벡터를 결과값으로 받고 여기서 softmax layer 혹은 CRF layer를 통해 태깅을 진행합니다.
또한, 더 성능을 높이고자 densely connected network를 추가했습니다.
5.2 Condtional Random Field

앞서 언급한 CRF layer에 대한 설명입니다.
양방향 구조의 LSTM을 사용했지만 특징 추출 시에만 각 time-step에 대한 특징을 효율적으로 추출할뿐,
예측시에는 과거, 미래의 출력과는 관계없이 독립적인 단점이 있다고 설명합니다. 이를 해결하기 위해서 논문에서는 CRF layer을 구성했다고 주장합니다.
CRF layer는 상태 전이 확률을 계산하고 해당 단점을 극복할 수 있다고 설명합니다.
5.3 Stacking RNNs with Residual Connection

ResNet에서 등장한 개념인 Residual connection에 대한 설명과 모델에서 이 구조를 채택했음을 설명하는 부분입니다.
5.4 Dropout

모델의 성능 향상을 위해 드롭아웃을 적용했으며, 그에 대한 설명 부분입니다.
Training Details
6.1 Pre-trained Word Embeddings

사전학습된 word embedding을 활용하는 것은 다양한 NLP task를 수행함에 있어 효율적인 방법이며, 해당 논문에서는 GloVe를 사용했다고 설명합니다. 훈련데이터에서 학습되지 않은 단어에 대해서는 OOV 토큰 처리를 했으며, OOV 토큰을 학습하기 위해서 randomly swap words을 수행했습니다.
6.2 Freezing Embeddings

앞선 사전 학습된 word vector는 훈련 과정 중 fine-tune되는데, 학습 초기에는 벡터값을 freezing하는 것보다 이 과정을 진행하는 것이 성능을 오히려 떨어트리며, 이를 방지하고자 학습 초기에는 가중치의 영향을 받지 않도록 freezing한다고 설명합니다.
6.3 Dynamic Batch Size

batch size를 점차 늘려가는 것에 대한 이점을 설명하고,
이를 채택했음을 설명하는 부분입니다.
6.4 Tagging Scheme

태깅의 구조에 대한 내용입니다.
IOBES 태깅은 BIO 태깅과 비교했을 때 통계적으로 유의미한 이점이 없으므로 BIO 태깅을 채택했음을 설명합니다.
6.5 Parameter Opimization

손실함수와 최적화에 대한 기본적인 내용입니다.
6.6 Hyperparameter Tuning

하이퍼파라미터 튜닝에 관한 내용입니다.
Evaluation
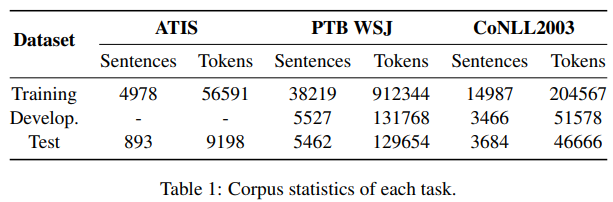
제안 모델을 Slot Tagging, POS Tagging, NER 세 가지의 task를 통해 평가합니다.
Table 1을 제시하며 각 Task에 대한 요약을 설명합니다.
7.1 Slot Tagging, 7.2 Part-of-Speech Tagging, 7.3 Named Entity Recognition

각 Task에 사용한 데이터셋에 대한 설명과 실험에서 데이터를 어떻게 사용했는지 그리고 평가지표를 어떤 방식을 취했는지에 대한 자세한 설명이 기재되어있습니다.
7.4 Baseline Models

character-level feature extraction에 쓰이는 CNN과 RNN을 논문에서 제안하는 모델과 비교하기 위해 구현했는데, 비교를 위한 실험이기에 CRF대신 softmax를 사용했음을 설명합니다.
Results and Discussion
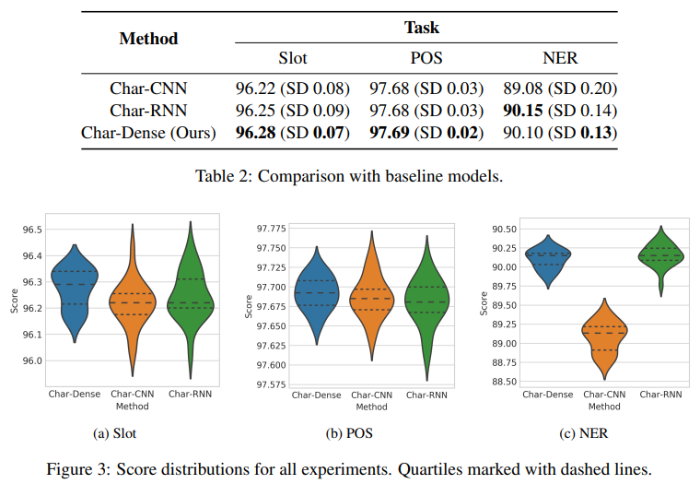
8.1 Experimental Results
논문에서는 제안한 모델과 앞서 언급한 두 가지의 baseline 모델을 심층적으로 분석하기 위해서
initial parameters를 다르게 설정하고 각각 20번씩 학습 후 분석했습니다.
Table 2와 Figure 3을 통해 평균 성능과 시각화 자료를 확인할 수 있습니다.
8.1.1 Slot Tagging
논문에서 제안하는 모델이 표와 그림을 통해 확인할 수 있듯이 가장 뛰어남을 입증했습니다.
평균 f1-score가 가장 높았으며, 그림과 같이 가장 변동성이 적어 모델이 견고함을 확인했습니다.
8.1.2 Part-of-Speech Tagging
Slot Tagging 유사한 형태를 보입니다.
마찬가지로 평균 accuracy 점수가 가장 높았으며, 그림과 같이 가장 변동성이 적어 우수함을 입증했습니다.
8.1.3 Named Entity Recognition
NER task에서는 평균 f1-score가 RNN 기법이 가장 높았지만,
논문에서 제안하는 모델이 다른 task에서처럼 모델이 견고하며 RNN은 그렇지 못하다.
8.2 Training Speed
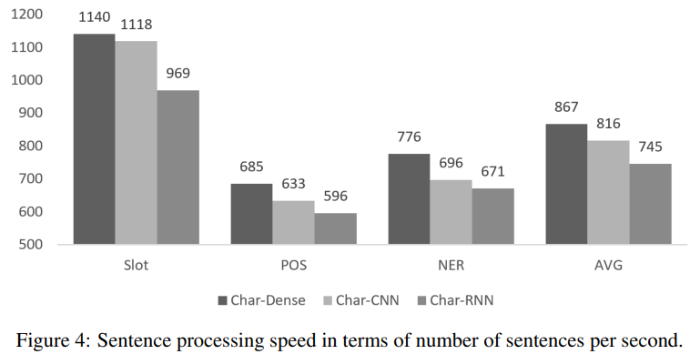

논문에서는 세 가지 모델을 비교하기 위해서 학습 속도에 대한 평가도 진행했습니다.
그 결과를 Figure 4를 통해 제시하고 있습니다.
논문에서 제안하는 모델 아키텍쳐가 학습 속도 면에서 나머지 두 가지 baseline 모델보다 약 6.29%, 16.32% 성능이 더 우수한 것으로 평가되었습니다.
8.3 Comparison with Published Results
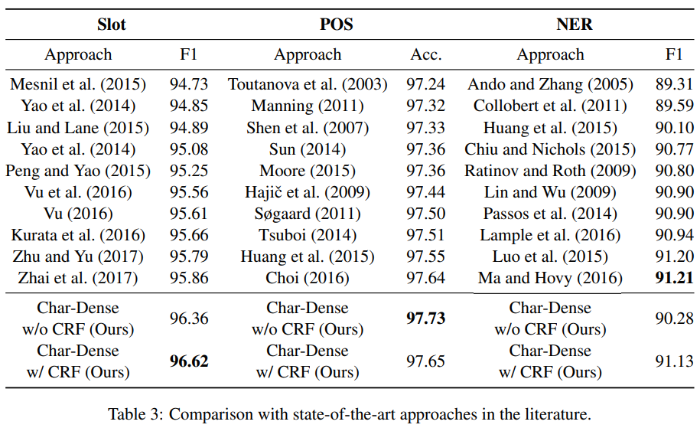
논문에서 제시한 각 task에 대한 다른 제안 모델들과 논문에서 제안하는모델(with CRF와 without CRF)에 대한 결과 표입니다.
결과를 통해 각 NLP task에 대해 우수한 성능을 보임을 확인할 수 있습니다.
CRF layer가 있을 경우 성능이 더 올라가는 경향이 있으며(아닌 경우도 있음), 각 task에 대해 SOTA 혹은 그것에 거의 근접하는 결과를 달성했습니다.
Conclusion and Future Work

논문의 결론 부분입니다.
논문에서는 densely connected network를 사용해 효율적이고 빠른 character-level feature을 생성하는 방법을 제안했습니다. 광범위한 평가에서 모델이 견고하고 높은 성능을 보임을 입증했습니다.
향후 연구 계획으로는 문법적으로 오류가 있는 문장에 대해서도 실험을 진행해 모델의 견고성을 평가할 것이며, NMT나 text summarization과 같은 다른 NLP task에 대해서도 실험을 진행할 것입니다.
공부하며 느낀 점
기존 CNN과 RNN 기반의 feature extraction 기법이 효율적이고 널리 사용되었는데,
이에 만족하지 않고 새로운 접근법으로 우수한 성능을 가진 모델을 제시한 것이 인상깊었습니다.
어떻게 보면 feature extraction을 하는 과정은 다양한 NLP task를 수행함에 있어 가장 기초적이면서도 중요한 과정이라고 할 수 있는데, 이에 우수한 성능을 나타내는 방법을 사용하면 각 task들에 대해서도 훌륭한 성과를 달성할 수 있을 것이라는 생각이 들었습니다. NMT, NLI, Sentiment Analysis 등 이런 세부적인 taks들에 대한 내용만 공부해야 된다고 생각했었는데 논문을 읽고 그것이 아님을 깨달았습니다.
자연어 처리 분야는 공부하면 할수록 학습할 내용이 많아지는 분야인 것 같습니다.
끈기를 가지고 열심히 공부하도록 하겠습니다.




댓글